The Intelligent Computer Research Center has developed an integrated memory-computing chip. The EDA toolchain is the first open-source integrated memory-computing hardware and software collaborative design toolchain in the world, breaking through the difficulties of automatic architecture generation and automatic algorithm deployment, supporting neural network acceleration and energy efficiency improvement by 1-2 orders of magnitude.
In the era of big data, the traditional von Neumann architecture is facing the bottleneck of the memory wall. Memory-centric computing is expected to break through the memory wall bottleneck, allowing computer performance and energy efficiency to continue to improve by one to two orders of magnitude. After more than a decade of research and exploration, memory-centric computing has made significant progress in various aspects such as devices, circuits, chips, and architecture, and has already been applied to neural network acceleration. However, memory-centric computing chips face the problem of lacking automated design tools. Facing the complex design space of chip architecture, it is difficult to achieve the optimization of chip PPA; for a variety of chip architectures, it is difficult to deploy complex and diverse neural networks.
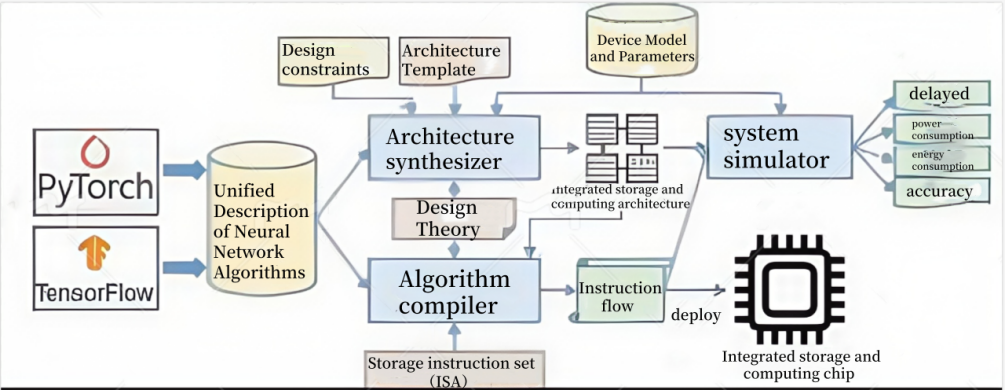
To address these challenges, the project team defined a neural network-oriented memory-computation integrated instruction set and architectural abstraction model, supporting the generality of EDA methods, and adaptable to a variety of memory-computation integrated devices and architectures. The team developed high-level synthesis methods and algorithmic compilation methods for memory-computation integrated architectures, achieving automatic generation from algorithmic descriptions to chip architectures and instructions, overcoming the difficulties in the automated design of memory-computation integrated chips, hardware-software co-optimization, and algorithm deployment. The project team developed the memory-computation integrated chip EDA toolchain PIM-Toolchain, which includes three core components:
1.Architecture Synthesizer PIMSYN-NN: Implements automatic generation of neuromorphic architectures from neural network algorithms described in PyTorch, and performs design space exploration to optimize architecture parameters and resource allocation;
2.Algorithm Compiler PIMCOMP-NN: Implements the automatic generation of instruction sequences from neural network algorithms described in PyTorch, and systematically optimizes task partitioning, data layout, operator mapping, pipeline scheduling, and instruction scheduling;
3.System Simulator PIMSIM-NN: Implements the simulation of instruction sequence execution performance and accuracy on the Processing-in-Memory (PIM) architecture. Based on an event-driven instruction-level simulation method, it achieves rapid and accurate simulation of performance, power consumption, and energy efficiency; based on device and circuit-level non-ideal factor modeling, it achieves accuracy simulation.
4.The PIM-Toolchain has been open-sourced on GitHub, which has enhanced the EDA software for processing-in-memory chips, facilitating design for the industry and academic research. The project team has collaborated with leading domestic enterprises that mass produce 28nm/22nm RRAM, integrating instruction sets and compilers into their RRAM processing-in-memory Chiplet prototype system. They successfully deployed a MoE large model, achieving an order of magnitude increase in throughput (token/s) compared to manual deployment.
downloadFile