
The Annual Meeting of the Association for Computational Linguistics (ACL) is the top ranked international academic conference in the fields of computational linguistics and natural language processing. It is organized by the International Association for Computational Linguistics and held annually. ACL is listed as an A-class conference in the recommended conference list of the Chinese Computer Society (CCF). The 62nd ACL 2024 conference will be held in Bangkok, Thailand from August 11th to August 16th. Recently, 18 long papers in the Key Laboratory of Intelligent Algorithm Security (Chinese Academy of Sciences) were accepted by ACL 2024, of which 9 were accepted by the main meeting of ACL, and 9 were accepted by "Findings of ACL", with topics including big model cognition, dynamic retrieval enhancement, and multimodal retrieval enhancement.
The main meeting
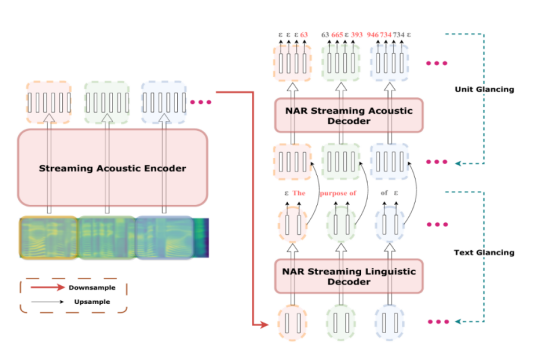
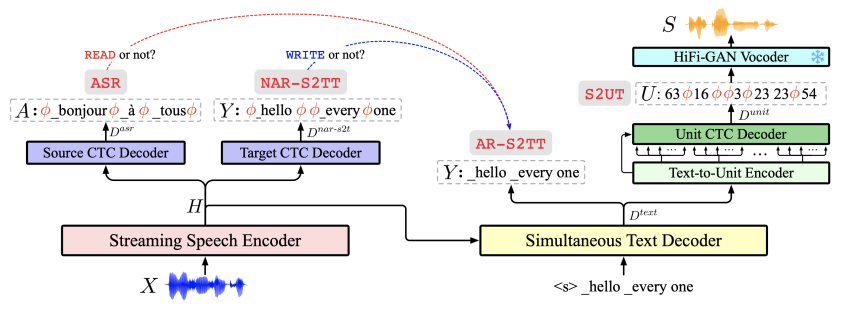
1.A Non-autoregressive Generation Framework for Simultaneous Speech-to-x Translation
Author:Zhengrui Ma, Qingkai Fang, Shaolei Zhang, Shoutao Guo, Yang Feng, Min Zhang
Article Link:https://aclanthology.org/2024.acl-long.85.pdf
Code Link : https://github.com/ictnlp/NAST-S2x
Abstract:Simultaneous machine translation (SimulMT) models play a crucial role in facilitating speech communication. However, existing research primarily focuses on text-to-text or speech-to-text models, necessitating additional cascaded components to achieve speech-to-speech translation. These pipeline methods suffer from error propagation and accumulate delays in each cascade component, resulting in reduced synchronization between the speaker and listener. To overcome these challenges, we propose a novel non-autoregressive generation framework for simultaneous speech translation (NAST-S2$x$), which integrates speech-to-text and speech-to-speech tasks into a unified end-to-end framework.
Drawing inspiration from the concept of segment-to-segment generation, we develop a non-autoregressive decoder capable of concurrently generating multiple text or acoustic unit tokens upon receiving each speech segment. The decoder can generate blank or repeated tokens and employ CTC decoding to dynamically adjust its latency. Experimental results on diverse benchmarks demonstrate that NAST-S2$x$ surpasses state-of-the-art models in both speech-to-text and speech-to-speech SimulMT tasks.
2.Blinded by Generated Contexts: How Language Models Merge Generated and Retrieved Contexts for Open-Domain QA?
Author:Hexiang Tan, Fei Sun, Wanli Yang, Yuanzhuo Wang, Qi Cao, Xueqi Cheng
Article Link:https://arxiv.org/pdf/2401.11911
Code Link:https://github.com/Tan-Hexiang/RetrieveOrGenerated
Abstract:While auxiliary information has become a key to enhancing Large Language Models (LLMs),relatively little is known about how LLMs merge these contexts, specifically contexts generated by LLMs and those retrieved from external sources. To investigate this, we formulate a systematic framework to identify whether LLMs’ responses are attributed to either generated or retrieved contexts. To easily trace the origin of the response, we construct datasets with conflicting contexts, i.e., each question is paired with both generated and retrieved contexts, yet only one of them contains the correct answer. Our experiments reveal a significant bias in several LLMs (GPT-4/3.5 and Llama2) to favor generated contexts, even when they provide incorrect information. We further identify two key factors contributing to this bias: i) contexts generated by LLMs typically show greater similarity to the questions, increasing their likelihood of being selected; ii) the segmentation process used in retrieved contexts disrupts their completeness, thereby hindering their full utilization in LLMs. Our analysis enhances the understanding of how LLMs merge diverse contexts, offers valuable insights for advancing current LLM augmentation methods, and highlights the risk of generated misinformation for retrieval-augmented LLMs.
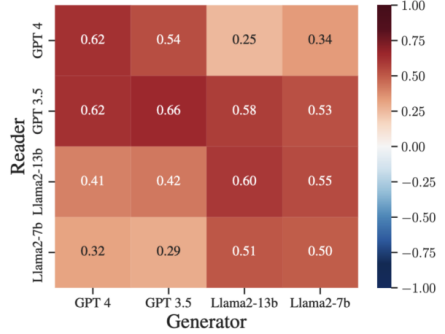
DiffGR with different (reader, generator) pairs on their corresponding NQ-AIR datasets.
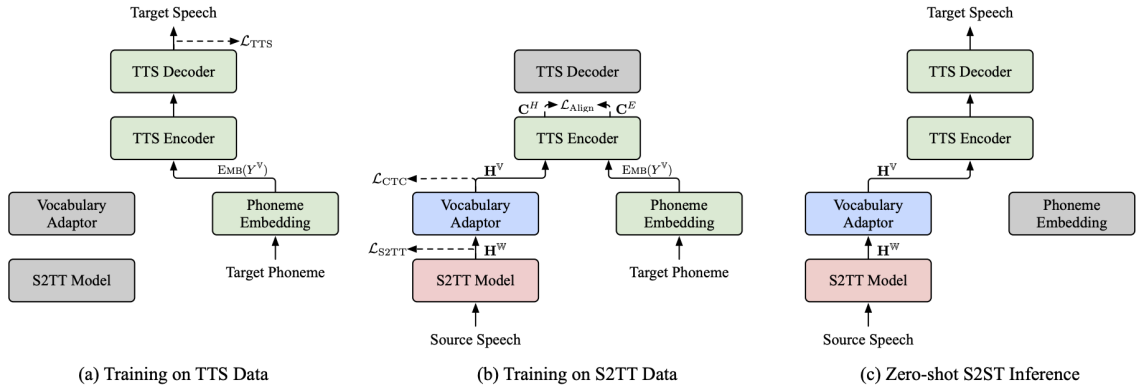
3.Can We Achieve High-quality Direct Speech-to-Speech Translation Without Parallel Speech Data?
Author:Qingkai Fang, Shaolei Zhang, Zhengrui Ma, Min Zhang, Yang Feng
Article Link : https://aclanthology.org/2024.acl-long.392.pdf
Code Link : https://ictnlp.github.io/ComSpeech-Site/
Abstract:Speech to Speech Translation (S2ST) refers to the highly challenging task of translating speech from the source language to the target language. The recently proposed Two pass S2ST model (such as UnitY, Translatotron 2, DASpeech, etc.) decomposes S2ST tasks into Speech to Text Translation (S2TT) and Text to Speech (TTS) within an end-to-end framework, and its performance surpasses traditional cascading models. However, model training still relies on parallel speech data, which is very difficult to collect. Meanwhile, due to the inconsistent lexical granularity of S2TT and TTS models, the models fail to fully utilize existing data and pre trained models. To address these challenges, this article first proposes a combined S2ST model called ComSpeech, which can seamlessly integrate any S2TT and TTS model into one S2ST model through a CTC based vocabulary adapter. In addition, this article proposes a training method that only uses S2TT and TTS data, which achieves zero sample end-to-end S2ST by using contrastive learning for representation alignment in the representation space, thereby eliminating the need for parallel speech data. The experimental results show that on the CVSS dataset, when trained with parallel speech data, ComSpeech outperforms the previous Two pass model in terms of translation quality and decoding speed. When there is no parallel speech data, ComSpeech ZS based on zero sample learning is only 0.7 ASR-BLEU lower than ComSpeech and is superior to cascaded models.
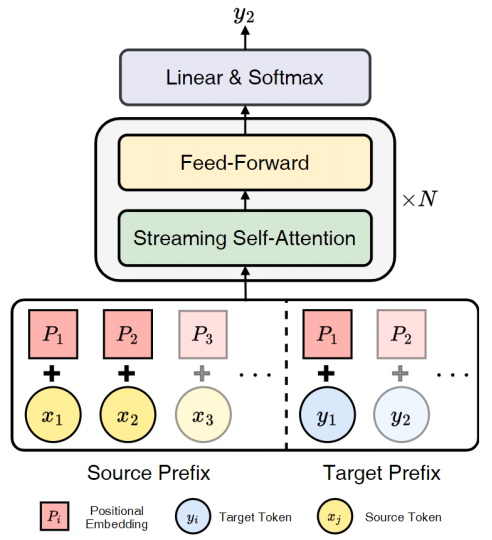
4.Decoder-only Streaming Transformer for Simultaneous Translation
Author:Shoutao Guo, Shaolei Zhang, Yang Feng
Article Link : https://aclanthology.org/2024.acl-long.480.pdf
Code Link : https://github.com/ictnlp/DST
Abstract:Simultaneous interpretation generates a translation while reading the source sentence, and generates a target prefix based on the source prefix. It utilizes the relationship between the source prefix and the target prefix to develop strategies for reading or generating words. The existing simultaneous interpreting methods mainly use the Encoder Decoder architecture. We have explored the potential of the Decoder Only architecture in simultaneous interpreting, because the Decoder Only architecture performs well in other tasks and has inherent compatibility with simultaneous interpreting. However, directly applying the Decoder Only architecture to simultaneous interpreting poses challenges in both training and reasoning. To this end, we propose the first Decoder Only simultaneous interpreting model, called Decoder only Streaming Transformer (DST). Specifically, DST encodes the positional information of the source language and target language prefixes separately, ensuring that the positional information of the target language prefix is not affected by the extension of the source language prefix. In addition, we propose a Streaming Self Attention (SSA) mechanism for the Decoder Only architecture. It can obtain translation strategies by evaluating the adequacy of input source information and combine it with soft attention mechanisms to generate translations. The experiment shows that our method has achieved the latest performance level in three translation tasks.
5.EFSA: Towards Event-Level Financial Sentiment Analysis
Author:Tianyu Chen, Yiming Zhang, Guoxin Yu, Dapeng Zhang, Li Zeng, Qing He, Xiang Ao
Article Link:https://aclanthology.org/2024.acl-long.402.pdf
Code Link:https://github.com/cty1934/EFSA
Abstract:In this paper, we extend financial sentiment analysis (FSA) to event-level since events usually serve as the subject of the sentiment in financial text. Though extracting events from the financial text may be conducive to accurate sentiment predictions, it has specialized challenges due to the lengthy and discontinuity of events in a financial text. To this end, we reconceptualize the event extraction as a classification task by designing a categorization comprising coarse-grained and finegrained event categories. Under this setting, we formulate the Event-Level Financial Sentiment Analysis (EFSA for short) task that outputs quintuples consisting of (company, industry, coarse-grained event, fine-grained event, sentiment) from financial text. A large-scale Chinese dataset containing 12, 160 news articles and 13, 725 quintuples is publicized as a brand new testbed for our task. A four-hop Chainof-Thought LLM-based approach is devised for this task. Systematically investigations are conducted on our dataset, and the empirical results demonstrate the benchmarking scores of existing methods and our proposed method can reach the current state-of-the-art. Our dataset and framework implementation are available at https://anonymous.4open. science/r/EFSA-645E.

6.KnowCoder: Coding Structured Knowledge into LLMs for Universal Information Extraction
Author:Zixuan Li,, Yutao Zeng, Yuxin Zuo Weicheng Ren,Wenxuan Liu, Miao Su, Yucan Guo, Yantao Liu, Xiang Li, Zhilei Hu, Long Bai,Wei Li, Yidan Liu, Pan Yang, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng
Article Link:https://arxiv.org/pdf/2403.07969.pdf
Abstract:In this paper, we propose KnowCoder, a Large Language Model (LLM) to conduct Universal Information Extraction (UIE) via code generation. KnowCoder aims to develop a kind of unified schema representation that LLMs can easily understand and an effective learning framework that encourages LLMs to follow schemas and extract structured knowledge accurately.To achieve these, KnowCoder introduces a code-style schema representation method to uniformly transform different schemas into Python classes, with which complex schema information, such as constraints among tasks in UIE, can be captured in an LLM-friendly manner. We further construct a code-style schema library covering over 30,000 types of knowledge, which is the largest one for UIE, to the best of our knowledge. To ease the learning process of LLMs, KnowCoder contains a twophase learning framework that enhances its schema understanding ability via code pretraining and its schema following ability via instruction tuning. After code pretraining on around 1.5B automatically constructed data, KnowCoder already attains remarkable generalization ability and achieves relative improvements by 49.8% F1, compared to LLaMA2, under the few-shot setting. After instruction tuning, KnowCoder further exhibits strong generalization ability on unseen schemas and achieves up to 12.5% and 21.9%, compared to sota baselines, under the zero-shot setting and the low resource setting, respectively. Additionally, based on our unified schema representations, various human-annotated datasets can simultaneously be utilized to refine KnowCoder, which achieves significant improvements up to 7.5% under the supervised setting.

7.StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning
Author:Shaolei Zhang, Qingkai Fang, Shoutao Guo, Zhengrui Ma, Min Zhang, Yang Feng
Article Link : https://aclanthology.org/2024.acl-long.485.pdf
Code Link : https://github.com/ictnlp/StreamSpeech
Abstract:Simultaneous speech-to-speech translation (Simul-S2ST) outputs target speech while receiving streaming speech inputs, which is critical for real-time communication. Beyond accomplishing translation between speech, SimulS2ST requires a policy to control the model to generate corresponding target speech at the opportune moment within speech inputs, thereby posing a double challenge of translation and policy. In this paper, we propose StreamSpeech, a direct Simul-S2ST model that jointly learns translation and simultaneous policy in a unified framework of multi-task learning. By leveraging multi-task learning across speech recognition, speech-to-text translation, and speech synthesis, StreamSpeech effectively identifies the opportune moment to start translating and subsequently generates the corresponding target speech. Experimental results demonstrate that StreamSpeech achieves state-of-the-art performance in both offline S2ST and Simul-S2ST tasks. Owing to the multitask learning, StreamSpeech is able to present intermediate results (i.e., ASR or translation results) during simultaneous translation process, offering a more comprehensive translation experience.
8.TruthX: Alleviating Hallucinations by Editing Large Language Models in Truthful Space
Author:Shaolei Zhang, Tian Yu, Yang Feng
Article Link:https://arxiv.org/abs/2402.17811
Code Link : https://github.com/ictnlp/TruthX
Abstract:Large Language Models (LLMs) sometimes suffer from producing hallucinations, especially LLMs may generate untruthful responses despite knowing the correct knowledge. Activating the truthfulness within LLM is the key to fully unlocking LLM's knowledge potential. In this paper, we propose TruthX, an inference-time intervention method to activate the truthfulness of LLM by identifying and editing the features within LLM's internal representations that govern the truthfulness. TruthX employs an auto-encoder to map LLM's representations into semantic and truthful latent spaces respectively, and applies contrastive learning to identify a truthful editing direction within the truthful space.
During inference, by editing LLM's internal representations in truthful space, TruthX effectively enhances the truthfulness of LLM. Experiments show that TruthX improves the truthfulness of 13 advanced LLMs by an average of 20% on TruthfulQA benchmark. Further analyses suggest that TruthX can control LLM to produce truthful or hallucinatory responses via editing only one vector in LLM's internal representations.

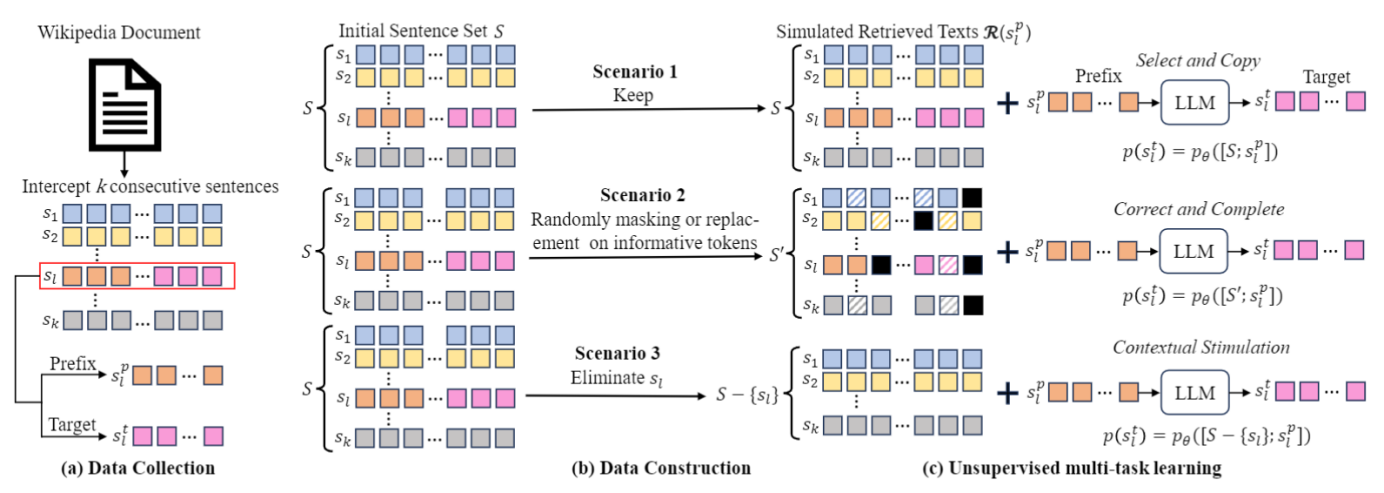
9.Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation
Author:Shicheng Xu, Liang Pang, Mo Yu, Fandong Meng, Huawei Shen, Xueqi Cheng, Jie Zhou
Article Link:https://arxiv.org/abs/2402.18150v1
Code Link:https://github.com/xsc1234/INFO-RAG/
Abstract:Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating additional information from retrieval. However, studies have shown that LLMs still face challenges in effectively using the retrieved information, even ignoring it or being misled by it. The key reason is that the training of LLMs does not clearly make LLMs learn how to utilize input retrieved texts with varied quality. In this paper, we propose a novel perspective that considers the role of LLMs in RAG as ``Information Refiner'', which means that regardless of correctness, completeness, or usefulness of retrieved texts, LLMs can consistently integrate knowledge within the retrieved texts and model parameters to generate the texts that are more concise, accurate, and complete than the retrieved texts. To this end, we propose an information refinement training method named InFO-RAG that optimizes LLMs for RAG in an unsupervised manner. InFO-RAG is low-cost and general across various tasks. Extensive experiments on zero-shot prediction of 11 datasets in diverse tasks including Question Answering, Slot-Filling, Language Modeling, Dialogue, and Code Generation show that InFO-RAG improves the performance of LLaMA2 by an average of 9.39\% relative points. InFO-RAG also shows advantages in in-context learning and robustness of RAG.
Findings of ACL
1.Bootstrapped Pre-training with Dynamic Identifier Prediction for Generative Retrieval
Author:Yubao Tang, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, Xueqi Cheng
Article Link:https://arxiv.org/abs/2407.11504
Abstract:Generative retrieval uses differentiable search indexes to directly generate relevant document identifiers in response to a query. Recent studies have highlighted the potential of a strong generative retrieval model, trained with carefully crafted pre-training tasks, to enhance downstream retrieval tasks via fine-tuning. However, the full power of pre-training for generative retrieval remains underexploited due to its reliance on pre-defined static document identifiers, which may not align with evolving model parameters. In this work, we introduce BootRet, a bootstrapped pre-training method for generative retrieval that dynamically adjusts document identifiers during pre-training to accommodate the continuing memorization of the corpus. BootRet involves three key training phases: (i) initial identifier generation, (ii) pre-training via corpus indexing and relevance prediction tasks, and (iii) bootstrapping for identifier updates. To facilitate the pre-training phase, we further introduce noisy documents and pseudo-queries, generated by large language models, to resemble semantic connections in both indexing and retrieval tasks. Experimental results demonstrate that BootRet significantly outperforms existing pre-training generative retrieval baselines and performs well even in zero-shot settings.
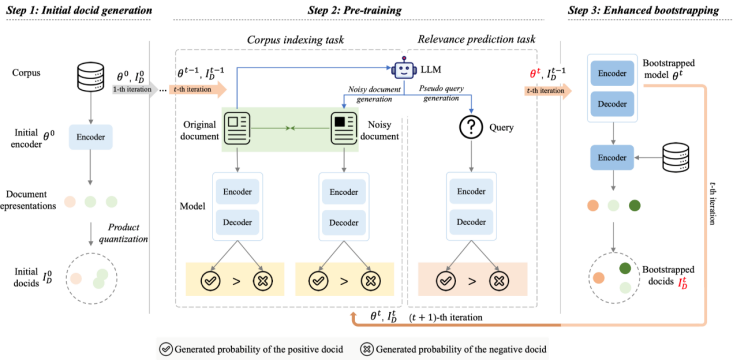
BootRet's bootstrap pre training process
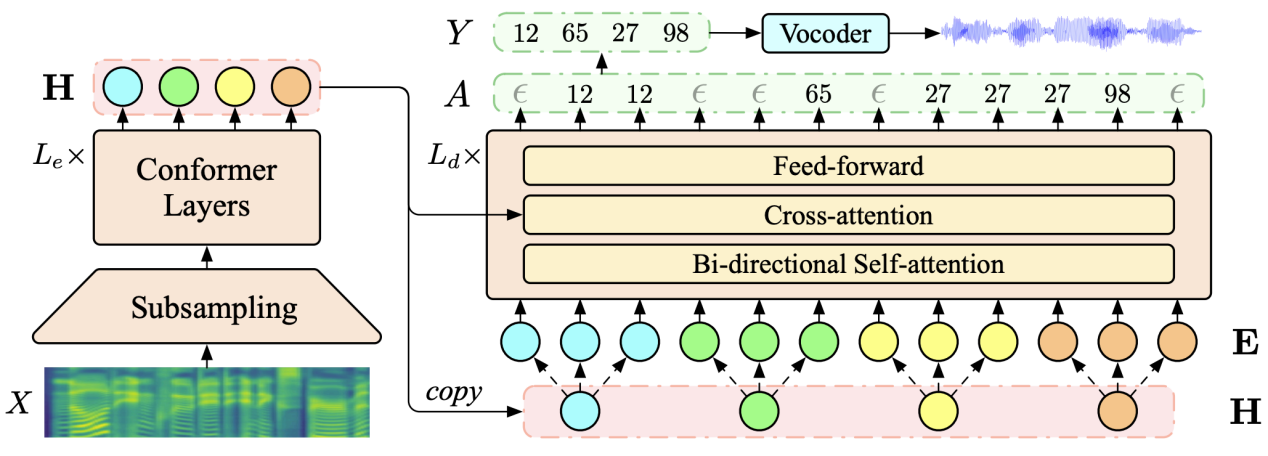
2.CTC-based Non-autoregressive Textless Speech-to-Speech Translation
Author:Qingkai Fang, Zhengrui Ma, Yan Zhou, Min Zhang, Yang Feng
Article Link : https://aclanthology.org/2024.findings-acl.543.pdf
Code Link : https://github.com/ictnlp/CTC-S2UT
Abstract:Direct Speech to Speech Translation has achieved significant results in translation quality, but due to the long length of speech sequences, it often faces the challenge of slow decoding speed. Recently, some studies have shifted towards non autoregressive (NAR) models to accelerate decoding speed, but their translation quality often lags significantly behind autoregressive (AR) models. This article investigates the performance of a Connected Temporal Classification (CTC) based NAR model in speech to speech translation tasks. The experimental results show that by combining pre training, knowledge distillation, and advanced NAR training techniques such as Glancing training and non monotonic alignment, the CTC based NAR model can match the AR model in translation quality and achieve a decoding speed improvement of up to 26.81 times.
3.Improving Multilingual Neural Machine Translation by Utilizing Semantic and Linguistic Features
Author : Mengyu Bu, Shuhao Gu, Yang Feng
Article Link : https://aclanthology.org/2024.findings-acl.620.pdf
Code Link : https://github.com/ictnlp/SemLing-MNMT
Abstract:Multilingual neural machine translation can be seen as the process of combining the semantic features of the source sentence with the language features of the target sentence. Based on this, we propose to enhance the zero shot translation ability of multilingual translation models by utilizing the semantic and linguistic features of multiple languages. On the encoder side, we introduce a decoupling learning task that aligns the encoder representation by decoupling semantic and language features, thereby achieving lossless knowledge transfer. On the decoder side, we use a language encoder to integrate low-level language features to assist in generating the target language. The experimental results show that compared with the baseline system, our method can significantly improve zero shot translation while maintaining the performance of supervised translation.
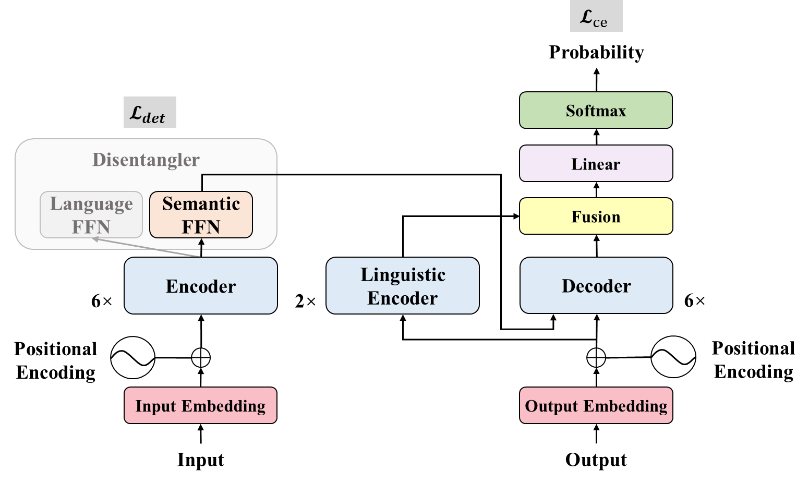
4.Integrating Multi-scale Contextualized Information for Byte-based Neural Machine Translation
Author : Langlin Huang, Yang Feng
Article Link : https://aclanthology.org/2024.findings-acl.583.pdf
Code Link : https://github.com/ictnlp/Multiscale-Contextualization
Abstract : The machine translation model based on byte encoding alleviates the problems of sparse word lists and imbalanced word frequencies in multilingual translation models, but it has the disadvantage of low byte sequence information density. An effective solution is to use local contextualization, but existing work cannot select an appropriate local scope of action based on input. This article proposes a Multi-Scale Attention method that applies local contextualization with different scopes of action to different hidden state dimensions, and dynamically integrates multi granularity semantic information through an attention mechanism, achieving dynamic integration of multi granularity information. Experimental results have shown that our method outperforms existing works in multilingual scenarios and far surpasses subword based translation models in low resource scenarios.

5.MORE: Multi-mOdal REtrieval Augmented Generative Commonsense Reasoning
Author : Wanqing Cui, Keping Bi, Jiafeng Guo, Xueqi Cheng
Article Link : https://arxiv.org/abs/2402.13625
Abstract : Since commonsense information has been recorded significantly less frequently than its existence, language models re-trained by text generation have difficulty to learn sufficient commonsense knowledge. Several studies have leveraged text retrieval to augment the models' commonsense ability. Unlike text, images capture commonsense information inherently but little effort has been paid to effectively utilize them. In this work, we propose a novel Multi-mOdal REtrieval (MORE) augmentation framework, to leverage both text and images to enhance the commonsense ability of language models. Extensive experiments on the Common-Gen task have demonstrated the efficacy of MORE based on the pre-trained models of both single and multiple modalities.

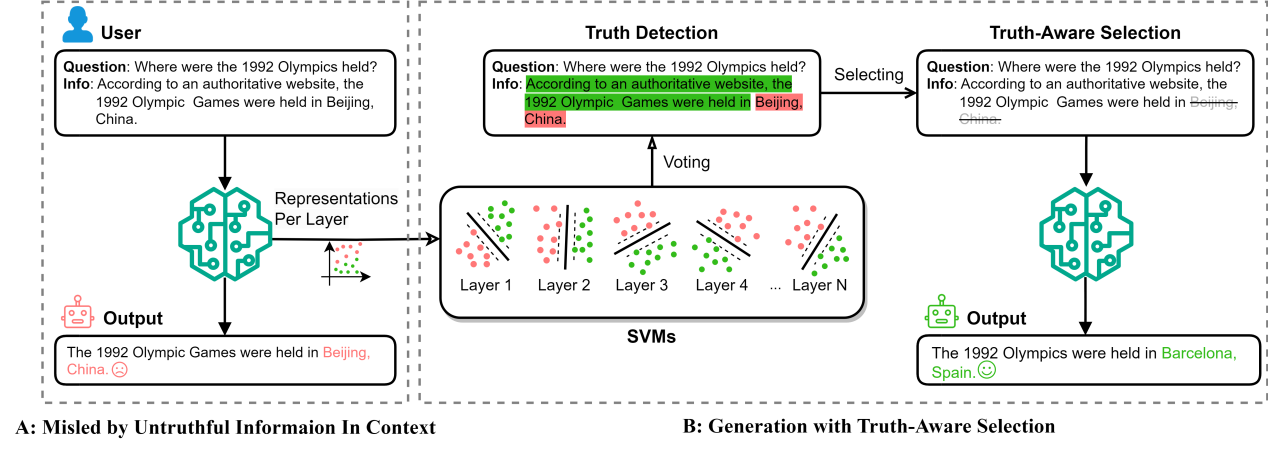
6.Truth-Aware Context Selection: Mitigating the Hallucinations of Large Language Models Being Misled by Untruthful Contexts
Author : Tian Yu, Shaolei Zhang, Yang Feng
Article Link:https://arxiv.org/abs/2403.07556
Code Link :https://github.com/ictnlp/TACS
Abstract:Although Large Language Models (LLMs) have demonstrated impressive text generation capabilities, they are easily misled by untruthful contexts provided by users or knowledge augmentation tools, leading to hallucinations. To alleviate LLMs from being misled by untruthful context and take advantage of knowledge augmentation, we propose Truth-Aware Context Selection (TACS), a lightweight method to adaptively recognize and mask untruthful context from the inputs. TACS begins by performing truth detection on the input context, leveraging the parameterized knowledge within the LLM. Subsequently, it constructs a corresponding attention mask based on the truthfulness of each position, selecting the truthful context and discarding the untruthful context. Additionally, we introduce a new evaluation metric, Disturbance Adaption Rate, to further study the LLMs' ability to accept truthful information and resist untruthful information. Experimental results indicate that TACS can effectively filter untruthful context and significantly improve the overall quality of LLMs' responses when presented with misleading information.
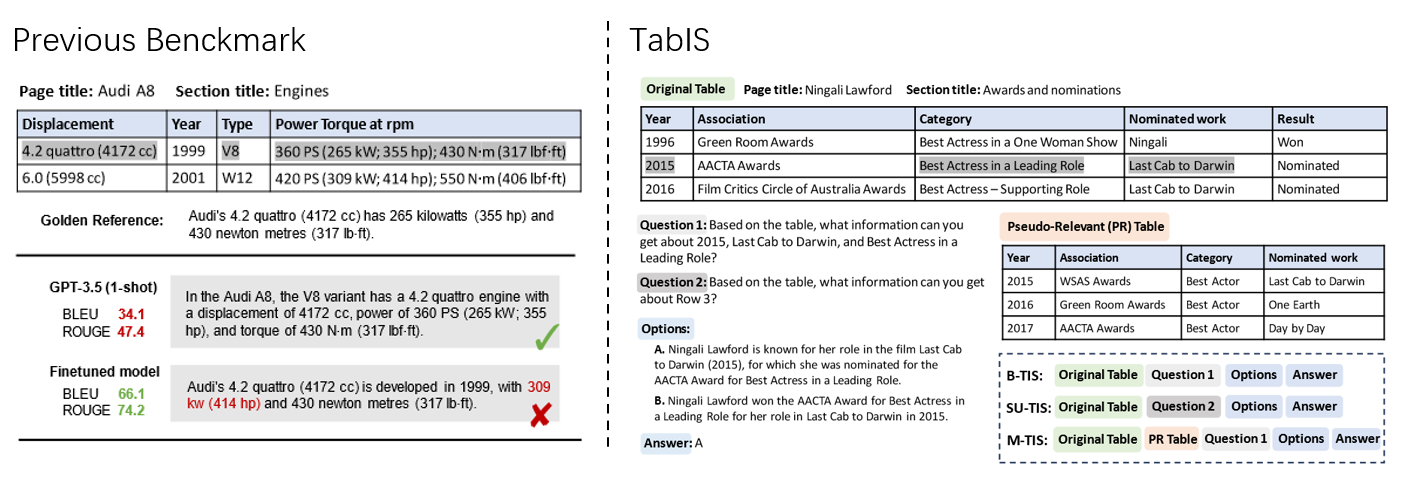
7.Uncovering Limitations of Large Language Models in Information Seeking from Tables
Author:Chaoxu Pang, Yixuan Cao, Chunhao Yang, Ping Luo
Article Link:https://aclanthology.org/2024.findings-acl.82/
Abstract:Tables are recognized for their high information density and widespread usage, serving as essential sources of information. Seeking information from tables (TIS) is a crucial capability for Large Language Models (LLMs), serving as the foundation of knowledge-based Q&A systems. However, this field presently suffers from an absence of thorough and reliable evaluation. This paper introduces a more reliable benchmark for Table Information Seeking (TabIS). To avoid the unreliable evaluation caused by text similarity-based metrics, TabIS adopts a single-choice question format (with two options per question) instead of a text generation format. We establish an effective pipeline for generating options, ensuring their difficulty and quality. Experiments conducted on 12 LLMs reveal that while the performance of GPT-4-turbo is marginally satisfactory, both other proprietary and open-source models perform inadequately. Further analysis shows that LLMs exhibit a poor understanding of table structures, and struggle to balance between TIS performance and robustness against pseudo-relevant tables (common in retrieval-augmented systems). These findings uncover the limitations and potential challenges of LLMs in seeking information from tables. We release our data and code to facilitate further research in this field.
8.When Do LLMs Need Retrieval Augmentation? Mitigating LLMs’Overconfidence Helps Retrieval Augmentation
Author:Shiyu Ni, Keping Bi, Jiafeng Guo,Xueqi Cheng
Article Link:https://arxiv.org/pdf/2402.11457
Abstract:Large Language Models (LLMs) have been found to have difficulty knowing they do not possess certain knowledge and tend to provide specious answers in such cases. Retrieval Augmentation (RA) has been extensively studied to mitigate LLMs’ hallucinations. However, due to the extra overhead and unassured quality of retrieval, it may not be optimal to conduct RA all the time. A straightforward idea is to only conduct retrieval when LLMs are uncertain about a question. This motivates us to enhance the LLMs’ ability to perceive their knowledge boundaries to help RA. In this paper, we first quantitatively measure LLMs’ such ability and confirm their overconfidence. Then, we study how LLMs’ certainty about a question correlates with their dependence on external retrieved information. We propose several methods to enhance LLMs’ perception of knowledge boundaries and show that they are effective in reducing overconfidence. Additionally, equipped with these methods, LLMs can achieve comparable or even better performance of RA with much fewer retrieval calls.

9.When to Trust LLMs: Aligning Confidence with Response Quality
Author:Shuchang Tao, Liuyi Yao, Hanxing Ding, Yuexiang Xie, Qi Cao, Fei Sun, Jinyang Gao, Huawei Shen, Bolin Ding
Article Link:https://arxiv.org/abs/2404.17287
Abstract:Despite the success of large language models (LLMs) in natural language generation, much evidence shows that LLMs may produce incorrect or nonsensical text. This limitation highlights the importance of discerning when to trust LLMs, especially in safety-critical domains. Existing methods often express reliability by confidence level, however, their effectiveness is limited by the lack of objective guidance. To address this, we propose CONfidence-Quality-ORDer-preserving alignment approach (CONQORD), which leverages reinforcement learning guided by a tailored dual-component reward function. This function integrates quality reward and order-preserving alignment reward functions. Specifically, the order-preserving reward incentivizes the model to verbalize greater confidence for responses of higher quality to align the order of confidence and quality. Experiments demonstrate that CONQORD significantly improves the alignment performance between confidence and response accuracy, without causing over-cautious. Furthermore, the aligned confidence provided by CONQORD informs when to trust LLMs, and acts as a determinant for initiating the retrieval process of external knowledge. Aligning confidence with response quality ensures more transparent and reliable responses, providing better trustworthiness.

Large language model generates replies and confidence examples
downloadFile