
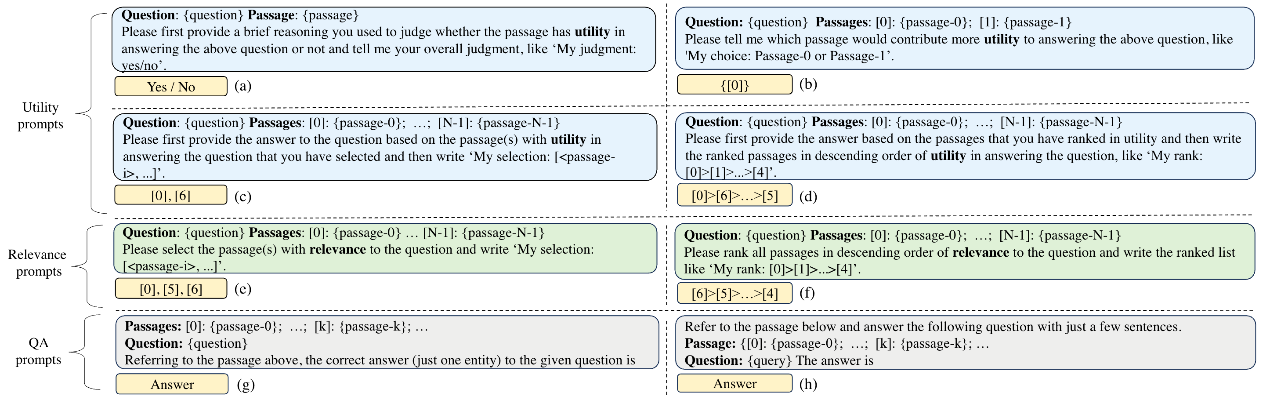
SIGIR It is A class A conference recommended by CCF of China Computer Society and enjoys A high academic reputation in related fields. The 47th ACM SIGIR International Conference on Research and Development of Information Search (The 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024) is scheduled to open in Washington, USA on July 18,2024. A total of 791 long articles were submitted at the conference, 159 of which were accepted, with an employment rate of about 20.1%. The Key Laboratory of Intelligent Algorithm Security (Chinese Academy of Sciences) has three papers accepted by SIGIR 2024, with topics include large model retrieval enhancement and sorting model against attack.
1.LoRec:Combating Poisons with Large Language Model for Robust Sequential Recommendation
Author: Zhang Kaike, Cao QI, Wu Yunfan, Sun Fei, Shen Huawei, Cheng Xueqi
Link to the paper: https: / / arxiv.org/pdf/2401.17723
Code link: https: / / github.com/Kaike-Zhang/LoRec
Content Introduction: The sequence recommendation system has been widely used in various recommendation scenarios due to its excellent ability to capture users' dynamic interests and project transfer patterns. However, due to the inherent openness of sequence recommendation systems, they are vulnerable to "poisoning" attacks, which inject false data into training data to manipulate the system for learning patterns, such as promoting specific commodities. Traditional defense methods mainly rely on assumptions or rules against known attacks, and it is difficult to effectively combat new or unknown attacks. To address this challenge, we propose an innovative framework that introduces rich open world knowledge from large-scale language models (LLM) into defense strategies to overcome the limitations of traditional defenses. In this paper, we present LoRec, an enhanced training calibration framework utilizing LLM, to improve the robustness of sequence recommendation systems in the face of "poison" attacks. LoRec includes an LLM-enhanced calibrator (LCT), which uses the knowledge of LLM to optimize the training process of the recommendation system and dynamically adjust the user weights to reduce the impact of attacks. By introducing open world knowledge of LLM, LCT is able to translate limited prior knowledge or rules into more general patterns that effectively defend against "poisoning" attacks. The combined experimental results show that LoRec as a general framework significantly improve the robustness of sequence recommendation systems.
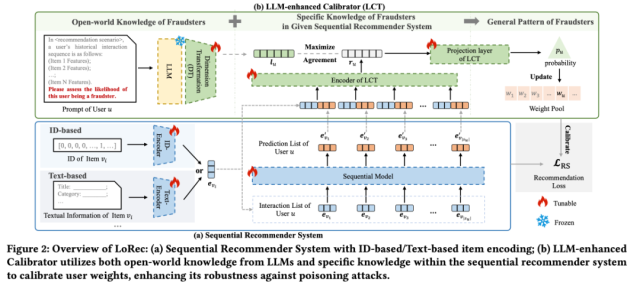
- Figure 1: LoRec frame diagram
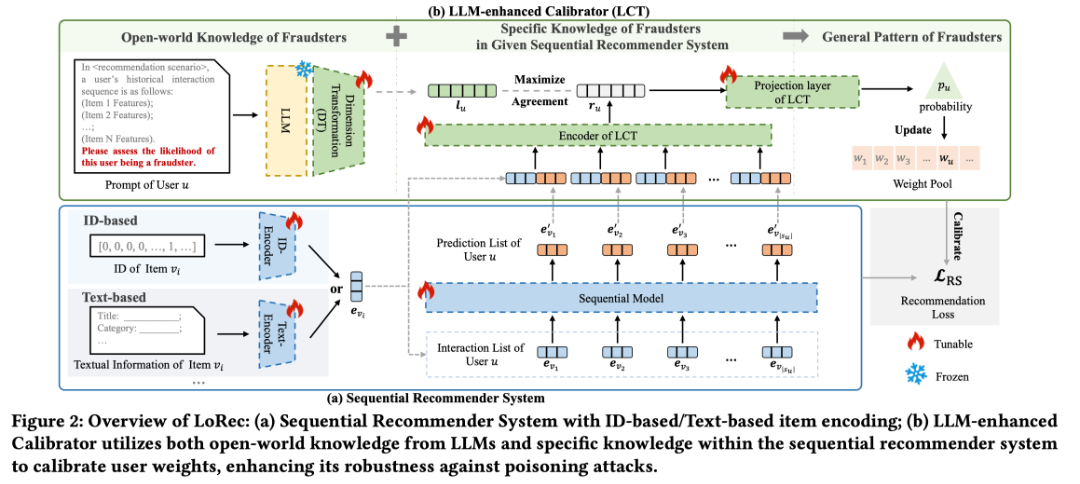
2.Invisible Relevance Bias: Text-Image Retrieval Models Prefer AI-Generated Images
Author: Xu Shicheng, Hou Danyang, Pang Liang, Deng Jingcheng, Xu Jun, Shen Huawei, Cheng Xueqi
Link to the paper: https: / / arxiv.org/abs/2311.14084
Content Introduction: With the application of generative models, the Internet is increasingly flooded with AI-generated content (AIGC), leading to both real content and AI-generated content being indexed into the search corpus. This paper explores the impact of AI-generated images on text-image search in this context. First, we constructed a benchmark containing real images and AI-generated images for this study. In this benchmark, the AI generated images with visual semantics sufficiently similar to the real image. Experiments with this benchmark reveal that the text-image retrieval model tends to rank the AI-generated images ahead of the real image, even if the images generated by the AI do not show the query-related visual semantics more than the real image. We refer to this bias as an invisible correlation bias. This bias was detected in retrieval models with different training data and architectures, including models trained from scratch and those pre-trained on a large number of image-text pairs, including dual encoder and fusion encoder models. Further exploration revealed that mixing AI-generated images with the training data of the retrieval model exacerbates the invisible correlation bias. These problems lead to a vicious cycle where AI-generated images have a higher chance of being exposed from large amounts of data, making them more likely to be incorporated into the training of retrieval models, and such training increases the invisible correlation bias. To address the above issues and clarify the underlying causes of intangible correlation bias, first, we introduce an effective training method to mitigate this bias. Subsequently, we apply our proposed debias approach to trace the reason for identifying invisible correlation bias, revealing that AI-generated image-induced image encoders embed additional information into their representations that allow the retriever to estimate higher correlation scores. The findings of this paper reveal the potential impact of AI-generated images on text-image retrieval and have implications for further research.
3.Are Large Language Models Good at Utility Judgments?
Author: Zhang Hengrui, Zhang Ruqing, Guo Jiafeng, Maarten de Rijke, Fan Yixing, Cheng Xueqi
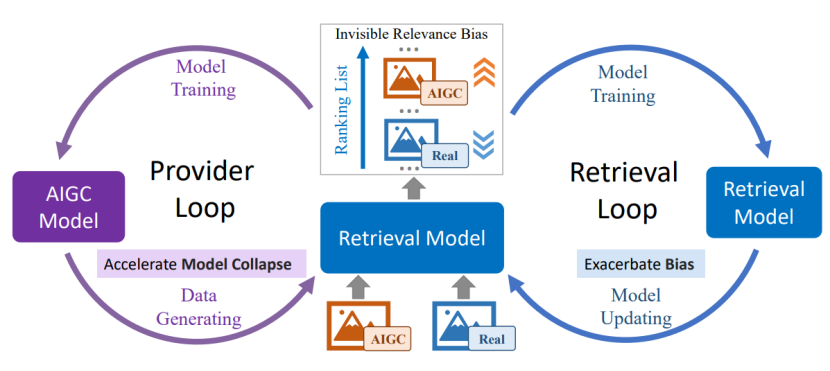
Content Introduction: Retrieval enhanced generation (RAG) is seen as a promising way to alleviate the hallucinations of large language models (LLMs), and has recently attracted wide attention from researchers. RAG largely relies on the retrieval of high-quality supporting information, and the existing retrieval system focuses on the correlation between the problem and the document, while the answer generation of RAG requires further judgment of the usefulness of the retrieved document for the problem. Recent studies have explored the ability of LLMs to judge the relevance of supporting information, but lack the exploration of the usefulness of LLMs in the generation of supporting information and answers. To this end, this paper thoroughly analyzes the usefulness judgment ability of LLMs in open field question answering tasks. Specifically, we designed a comprehensive set of benchmarks for usefulness judgments and performed a series of experiments on five representative LLMs. The experiment found that: (i) ChatGPT can distinguish the difference between problems and documents; (ii) the input form, output requirements, input order and other factors have a great influence on the usefulness judgment ability of the large model; (iii) increasing the usefulness judgment to the existing dense vector retrieval results can improve the effect of answer generation more than the correlation judgment only. Further, we designed a simple and effective k-sampling method that can significantly improve the usefulness judgment ability of large models, thus providing high-quality supporting information for answer generation.
- Figure 3: Schematic diagram of the instructions corresponding to the different input methods of the large language models
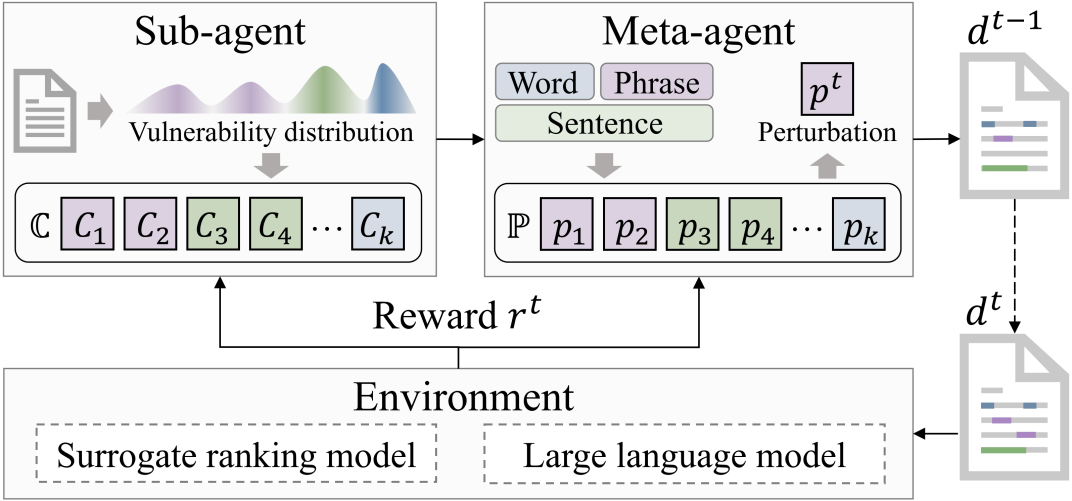
4.Multi-granular Adversarial Attacks against Black-box Neural Ranking Models
Author: Liu Yulu, Zhang Ruqing, Guo Jiafeng, Maarten de Rijke, Fan Yixing, Cheng Xueqi
Content Introduction: Adversarial ranking attack has attracted wide attention for its ability to effectively mine neural ranking model vulnerabilities and enhance its robustness. The traditional ranking attack method uses a single granular disturbance (word level or sentence level) to attack the target document. However, restricting perturbations to a single granularity level may reduce the flexibility to generate antagonistic samples and thereby attenuate the potential threat of attack. However, the direct introduction of a multigranularity perturbation faces the combinatorial explosion problem, in which the attacker needs to identify the optimal combination of perturbations on all possible granularity, location, and text fragments. To address this challenge, this paper transforms multi-granular adversarial attacks into a sequential decision process in which the perturbation in the next attack step is affected by the perturbation in the current attack step.
Specifically, this paper uses reinforcement learning to perform multi-grained attacks, utilizes two agent collaboration to identify multi-granular vulnerabilities as attack targets, and organizes perturbation candidates as the final perturbation sequence. Experimental results show that our attack method significantly surpasses existing methods in terms of attack effectiveness and invisibility, effectively revealing the universal adversarial vulnerability problem of existing neural ranking models, and can promote the evaluation and establishment of robust and credible information retrieval systems.
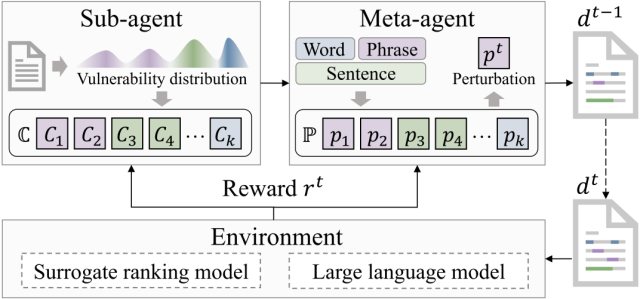
- Figure 4: Multi-granular adversarial ranking attack framework based on reinforcement learning
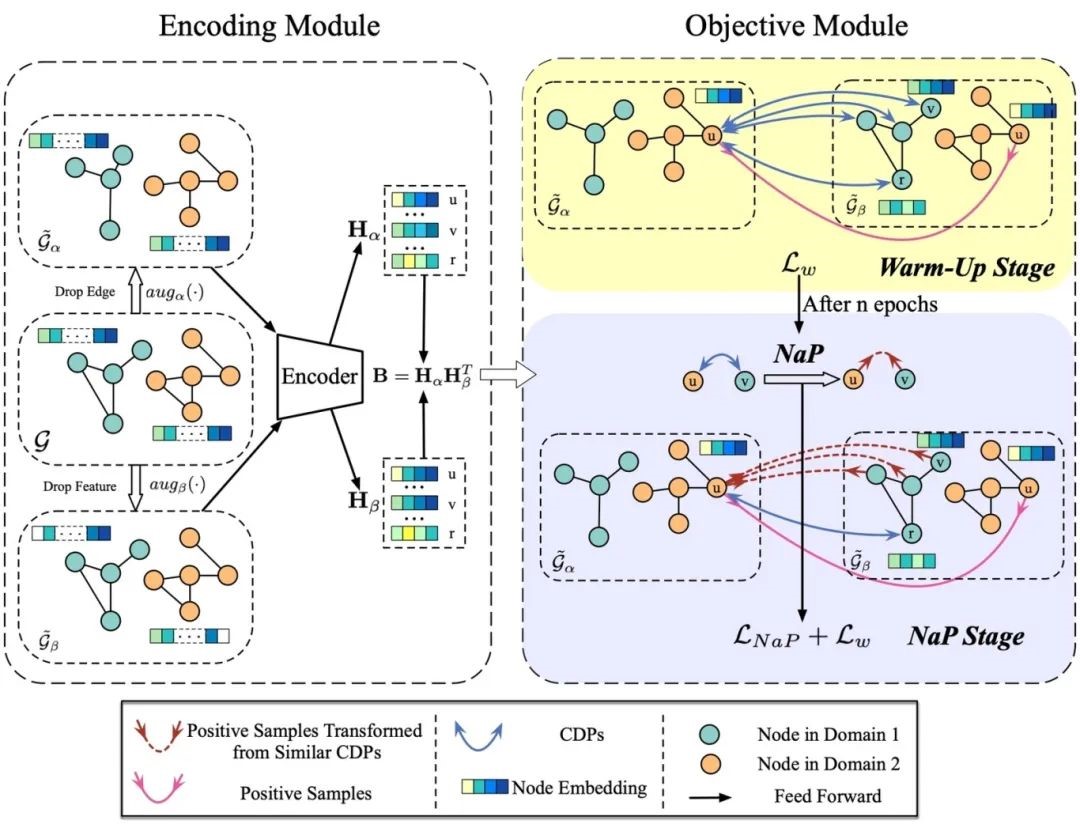
5.Negative as Positive: Enhancing Out-of-distribution Generalization for Graph Contrastive Learning
Author: Wang Zixu, Xu Bingbing, Yuan Yige, Shen Huawei, Cheng Xueqi
Link: https: / / doi.org/10.1145/3626772.3657927
Content introduction: In this work, we found that the distributional generalization ability of the traditional graph comparison learning method needs to be improved. After analysis and verification, we believe that it is precisely because the cross-domain pair is always taken as a negative sample that the inter-domain distribution offset is increased, which ultimately reduces the distribution generalization ability of the model. Based on this, we propose a method to convert the most semantically similar cross-domain negative sample pairs into positive samples i. e., Negative as Postive (NaP). Comprehensive experiments show that our method NaP significantly improves the OOD generalization ability of the graph contrast learning method.
downloadFile