
The LREC-COLING 2024 conference is jointly organized by the ELRA Language Resources Association (ELRA) in the field of computational linguistics and the International Committee on Computational Linguistics (ICCL), and will be held in Turin, Italy from May 20th to 25th. Eight papers of Key Laboratory of Intelligent Algorithm Security (Chinese Academy of Sciences) were employed by LREC-COLING 2024.
1.DRAMA:Dynamic Multi-Granularity Graph Estimate Retrieval over Tabular and Textual Question Answering
Author:Yuan Ruize, Ao Xiang, Zeng Li, He Qing
Content Introduction: The TableTextQA task, which aims to find answers to questions from mixed data that combines tables and linked text, is receiving increasing attention. Tabular line-based methods already presented have shown remarkable validity. However, they have some limitations: (1) the lack of row interaction; (2) the long input length; and (3) the complex reasoning steps that are difficult to derive efficiently in multi-hop QA tasks. Therefore, this paper proposes a new method: multi-granular retrieval (Dynamic Multi-Granularity Graph Estimate Retrieval, DRAMA). The method introduces a mechanism of interaction between multiple lines. Specifically, the knowledge base is used to store each granular feature, thus facilitating the construction of heterogeneous graphs containing the structural information of tables and linked text. In addition, the dynamic graph attention network (DGAT) is designed to assess the transfer of problem attention in multi-hop problems and dynamically eliminate connections to irrelevant information. This study yielded experimental results for SOTA on the widely used HybridQA and TabFact publicly available datasets.
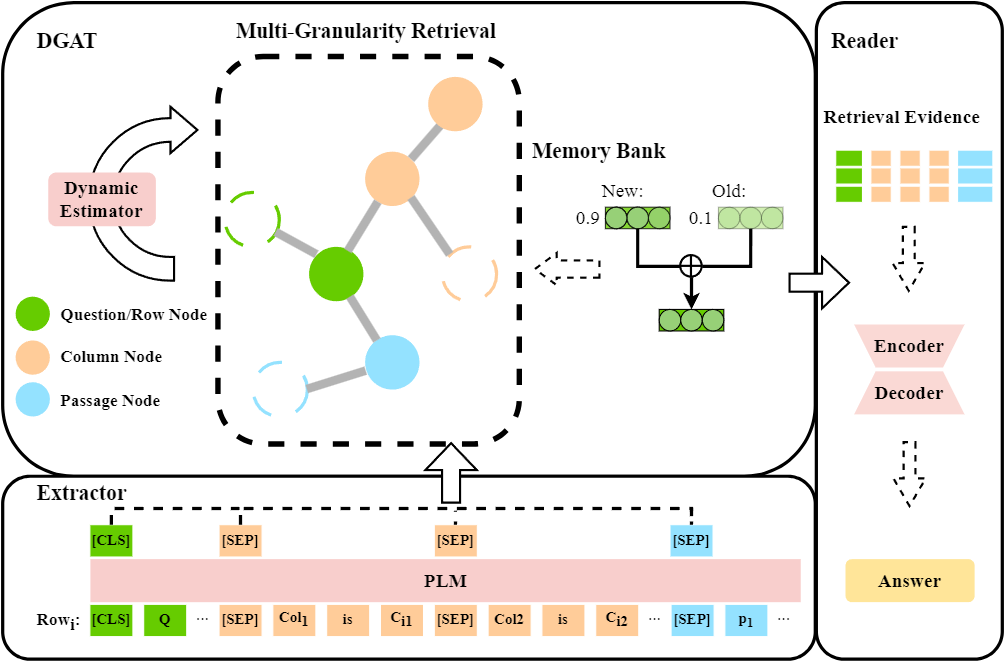
Figure 1: Structure diagram of the DRAMA model
2.Distillation with Explanations from Large Language Models
Author:Zhang Hanyu, Wang Xiting, Ao Xiang, He Qing
Content Introduction: Interpretation of natural language forms is crucial to the interpretability of AI models. However, training models to generate high-quality natural language interpretations is a challenge because training requires a large number of human-written interpretations, which means a high cost. At present, large language models such as ChatGPT and GPT-4 have made significant progress in various natural language processing tasks. Large models also provide explanations of corresponding answers. It is a more economical choice to use large models for data annotation. However, a key problem is that the answers provided by the large model are not completely accurate and may introduce noise to the task output and interpretation generation. To solve this problem, this paper proposes a new mechanism for interpretation-assisted distillation using large models. Studies have observed that although large model-generated answers may be incorrect, their interpretations are often consistent with the answers. Using this consistency, this paper combines the answers and explanations generated by real labels and large models to generate more accurate answers and corresponding explanations simultaneously through the consistency model. The experimental results show that the method can improve the accuracy and generate a more consistent explanation with the model answer.
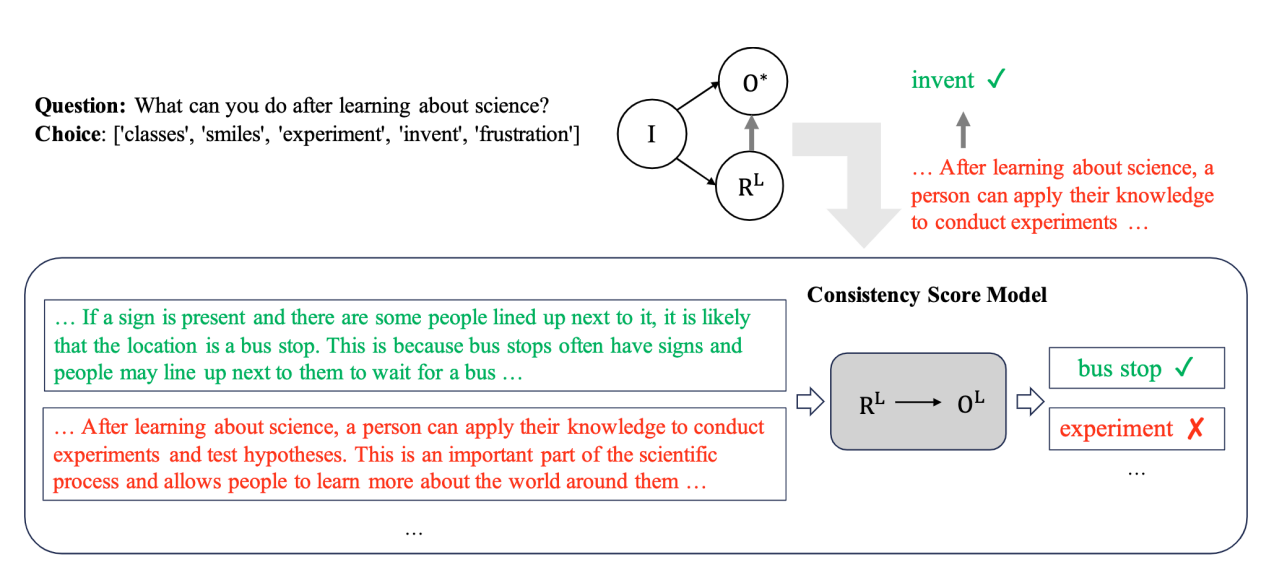
Figure 2: Size model knowledge distillation collaborative modeling framework
3.Self-Improvement Programming for Temporal Knowledge Graph Question Answering
Author: Chen Zhuo, Zhang Zhao, Li Zixuan, Wang Fei, Zeng Yutao, Jin Xiaolong, Xu Yongjun
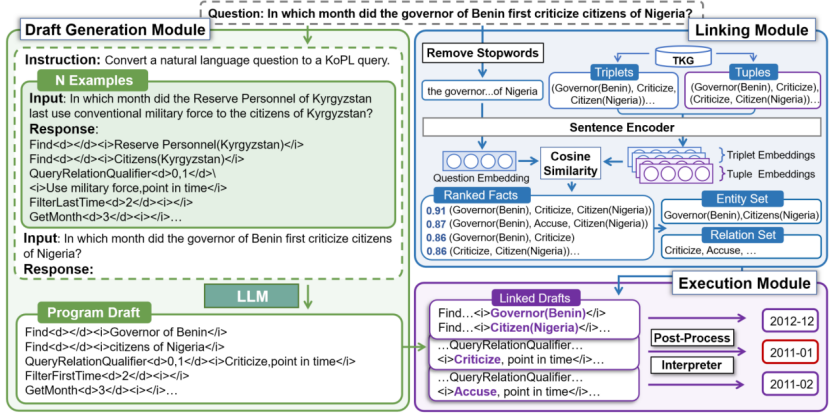
Content Introduction: The temporal knowledge graph aims to answer questions with temporal intentions by referring to the temporal knowledge graph. The core challenge of this task is to understand the complex semantic information about multiple types of time constraints (e. g., before, first time). Existing methods implicitly model time constraints by learning the time-aware embeddings of questions and candidate answers, making it difficult to fully understand the problem semantics. The semantic resolution-based method enables the explicit modeling of the problem constraints by generating logical queries with symbolic operators. Inspired by this, this paper designs the basic timing operator and proposes a novel self-improvement knowledge programming method, Prog-TQA. Specifically, Prog-TQA uses the context learning ability of a Large Language Model (LLM) to understand the combined time constraints in the problem, generating corresponding program drafts based on a given example. Then, the program draft is aligned to TKG using the link module and the program is finally executed to retrieve the answers. To enhance the understanding of the problem, Prog-TQA adopts a self-improvement strategy to guide LLM to understand complex problems using a high-quality self-generated program. Experiments demonstrate that the Prog-TQA method achieves significant performance gains on the widely used MultiTQ and CronQuestions datasets.
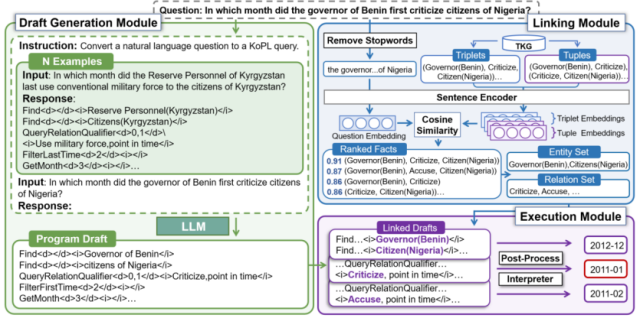
- Figure 3: The Prog-TQA time-sequence question-answering frame
4.Class-Incremental Few-Shot Event Detection
Authors: Zhao Kailin, Jin Xiaolong, Bai Long, Guo Jiafeng, Cheng Xueqi
Link to the paper: http: / / arxiv.org/abs/2404.01767
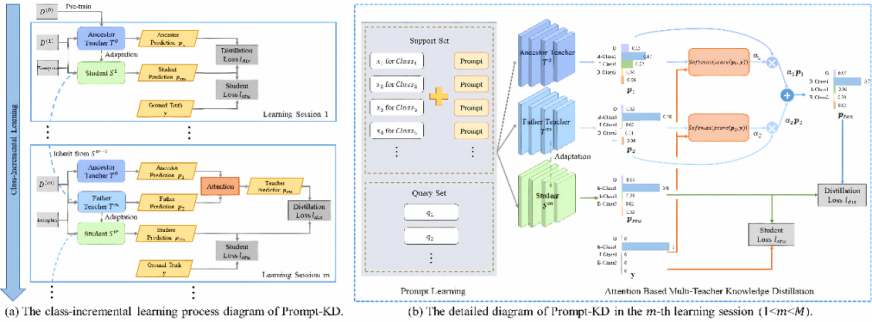
Introduction: Event detection is one of the basic tasks in information extraction and knowledge graph. At the same time, an event detection system in a real-world scenario usually requires constantly processing new incoming event categories. Due to the time-consuming labeling of a large number of unannotated samples, these new categories usually have only a small number of annotated samples. Based on this, this paper presents a new task called class-incremental few-sample event detection. However, there are two problems in this task, namely the old knowledge forgetting problem and the new category overfitting problem. To address these issues, this paper further proposes a novel knowledge-based distillation and knowledge-based method for cue learning, Prompt-KD. Specifically, to solve the problem of old knowledge forgetting, Prompt-KD adopts the knowledge distillation framework of the two-teacher model for the one-student model, while adopting the attention mechanism to balance the different importance of the two teacher models. Moreover, in order to alleviate the problem of the new category overfitting caused by small sample scenarios, Prompt-KD adopts a course-learning-based cue learning mechanism to reduce the dependence on labeled samples by stitching together an instruction containing semantic information behind the support set samples. Two standard FewEvent and MAVEN event detection datasets, were used for validation. Experimental results show that the Prompt-KD model performs better than the baseline model in different datasets, tasks and learning stages, verifying the effectiveness.
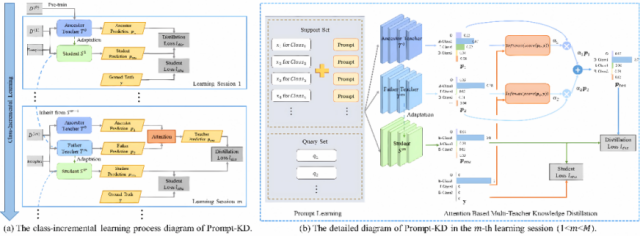
- Figure 4: Schematic diagram of the Prompt-KD model
- 5.Nested Event Extraction upon Pivot Element Recognition "
- Author: Ren Weicheng, Li Zixuan, Jin Xiaolong, Bai Long, Su Miao, Liu Yantao, Guan Saiping, Guo Jiafeng, Cheng Xueqi
- Link to the paper: https: / / arxiv.org/abs/2309.12960
- Code link: https: / / github.com/waysonren/PerNee
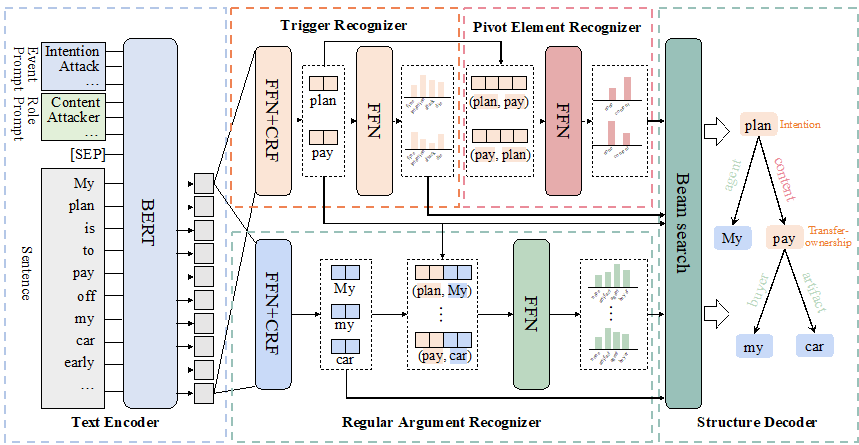
- Content Introduction: Nested event extraction is designed to extract complex event nested structures, where the nested structure refers to an event recursively containing other events as its elements. Nested events have a core node called Pivot Elements (PEs), which act as both arguments for external nested events and trigger words for internal nested events, and connect them into nested structures. This particular feature of PEs poses challenges to existing nested event extraction methods that do not handle the dual identity of PEs well. Therefore, this paper proposes a new model, called PerNee, which extracts nested events mainly based on identifying PEs. Specifically, PerNee first identifies trigger words for internally and externally nested events and further identifies PEs by classifying the types of relationships between trigger word pairs. The model also uses cue learning to integrate information about event types and meta-roles to obtain better trigger words and meta-semantic representations. Furthermore, existing nested event extraction datasets (such as Genia11) are limited to specific areas and can trigger fewer types of nested events. For this, we classify the nested events in the general domain and construct a new common domain of nested event extraction dataset, called ACE2005-Nest. Experimental results show that PerNee achieves state-of-the-art performance on ACE2005-Nest, Genia11, and Genia13, and is able to efficiently extract nested events.
-
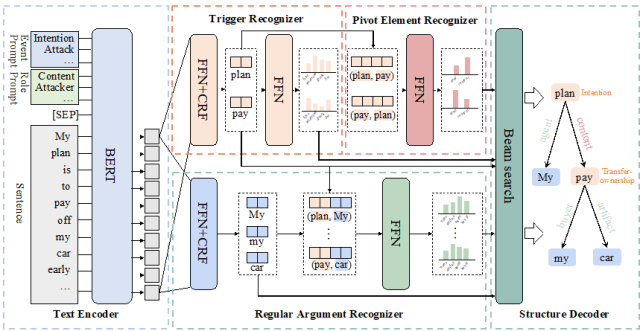
- Figure 5: The overall framework of the PerNee model
6.Few-shot Link Prediction on Hyper-relational Facts "
Author: Kui Jiyao, Guan Saiping, Jin Xiaolong, Guo Jiafeng, Cheng Xueqi)
Link to the paper: https: / / arxiv.org/abs/2305.06104
Code link: https: / / github.com/JiyaoWei/MetaRH
Content introduction: Hyperrelational events are composed of main triples (head entity, relationship, tail entity) and auxiliary attribute value pairs, which are widely present in the real world knowledge graph.Link prediction of hyper-relational events (LPHFs) are designed to predict missing elements in hyper-relational events to help populate and enrich the knowledge graph. However, existing studies of LPHFs often require a large amount of high-quality data. They ignore small-sample relationships with limited instances that are common in the real world. Therefore, we introduce a new task-small sample link prediction in hyperrelationship events (FSLPHFs). This task aims to predict missing entities in hyper-relational events, but with a limited number of supporting instances of relationships. To address the FSLPHFs problem, we propose the MetaRH model, which learns meta-relational information in hyper-relational events. MetaRH It includes three modules: relationship learning, specific support set adjustment, and query reasoning. By capturing meta-relationship information from limited support instances, MetaRH can accurately predict missing entities in the query. Since there is no dataset for this new task, we constructed three datasets to verify the effectiveness of MetaRH. Experimental results on these datasets show that MetaRH significantly outperforms the existing representative models.
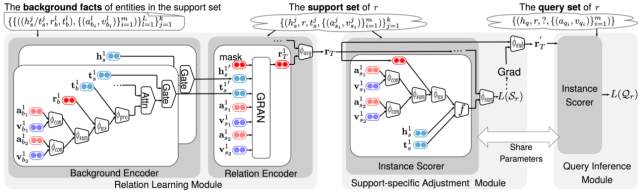
- Figure 6: The overall framework of the MetaRH model
7.Selective Temporal Knowledge Graph Reasoning
Author: Hou Zhongni, Jin Xiaolong, Li Zixuan, Bai Long, Guo Jiafeng, Cheng Xueqi
Link to the paper: http: / / arxiv.org/abs/2404.01695
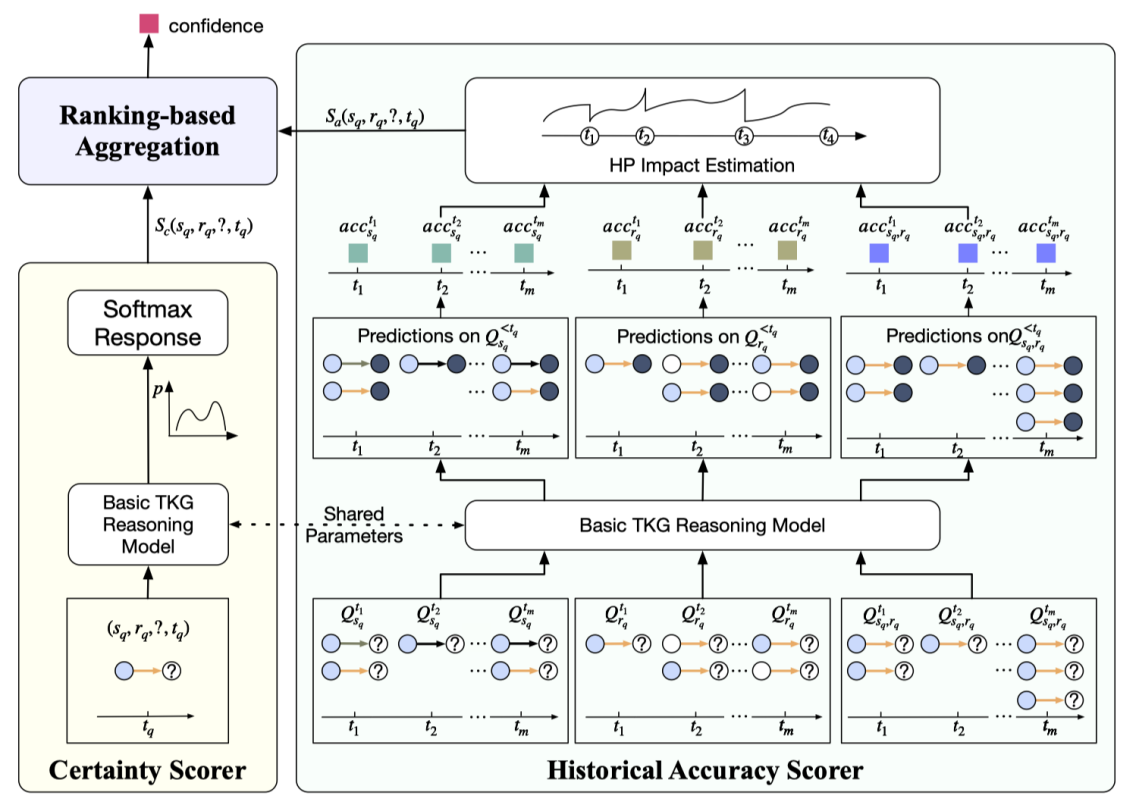
Content Introduction: The Temporal Knowledge Graph (TKG) prediction task aims to predict future knowledge based on a given historical fact, which has received wide attention in recent years. At present, TKG prediction task has shown good application prospects in many fields, such as financial analysis, disaster early warning, crisis event response, etc. However, these domains are often risk-sensitive, and false or unreliable predictions can have extremely serious consequences. Due to the complex complexity of a large number of entities, the prediction results of relevant knowledge have some uncertainty. Existing prediction models do not output all of their predicted results, which inevitably output low quality or even wrong predictions, bringing potential risks. To this end, this paper proposes the selection prediction mechanism of TKG to help existing models to select prediction rather than indiscriminate prediction. To achieve the choice prediction of TKG, this paper further proposes the history-based confidence estimator CEHis. CEHis first calculates the confidence of the prediction results of existing models and then rejecpredictions with low confidence. Among them, CEHis considers two kinds of information, namely the certainty of current prediction and the accuracy of historical prediction. The experimental results show that the proposed CEHis can significantly reduce the uncertainty of the model prediction results, and then realize the control of the predicted risk.
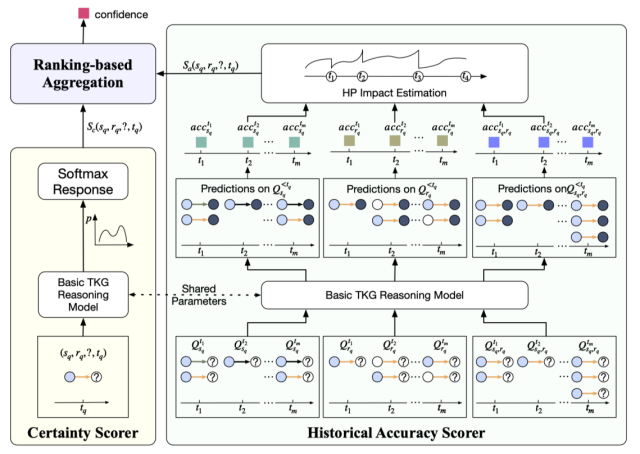
- Figure 7: Schematic diagram of the CEHis model
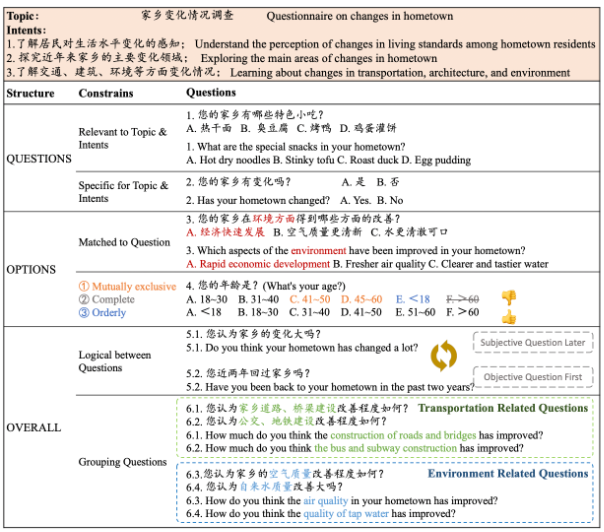
8.Thesis title: Qsnail: A Questionnaire Dataset for Sequential Question Generation
Author: Lei Yan, Pang Liang, Wang Yuanzhuo, Shen Huawei, Cheng Xueqi
Link to the paper: https: / / arxiv.org/pdf/2402.14272.pdf
Code link: https: / / github.com/LeiyanGithub/qsnail
Content Introduction: The questionnaire is a professional research method used for the qualitative and quantitative analysis of human views, preferences, attitudes, and behaviors. However, the design of the questionnaire requires considerable manpower and time, so we considered allowing the model to automatically generate questionnaires that meet human needs. The questionnaire consisted of a series of questions required to meet fine constraints involving the questions, options and the overall structure. Specifically, questions should be relevant to have clarity and pertinence for a given research topic and intentions. The Options should be tailored to the problem, ensuring that they are mutually exclusive, complete and in proper order. Furthermore, the problem order should follow a logical order, such as related topics grouped together. Therefore, there are great challenges in automatically generating questionnaires, mainly due to the lack of high-quality questionnaire datasets. To address the above questions, we present Qsnail, the first dataset specifically constructed for the questionnaire generation task, which includes 13,168 human-written questionnaires collected on an online platform. Further, we conduct experiments on Qsnail, and the results show that the retrieval model and the traditional generative model do not fully conform to the given research topic and intention and are weakly correlated. Although large language models are more closely related to research topics and intentions, there are significant limitations in diversity and degree of specificity. The model is immediately enhanced by chain thinking prompt and fine-tuning, and the questionnaire generated by the language model is still not comparable to the questionnaire written by humans. Therefore, the questionnaire generation is challenging and requires further investigation.
downloadFile