Two papers titled "AVM-BTB: Adaptive and Virtualized Multi-level Branch Target Buffer" and《Cambricon-D: Full-Network Differential Acceleration for Diffusion Models》, authored by researchers from the State Key Lab of Processors, Insititute of Computing Technology, CAS, were accepted by ISCA2024 (International Symposium on Computer Architecture), one of the top-tier international conference on computer architecture.
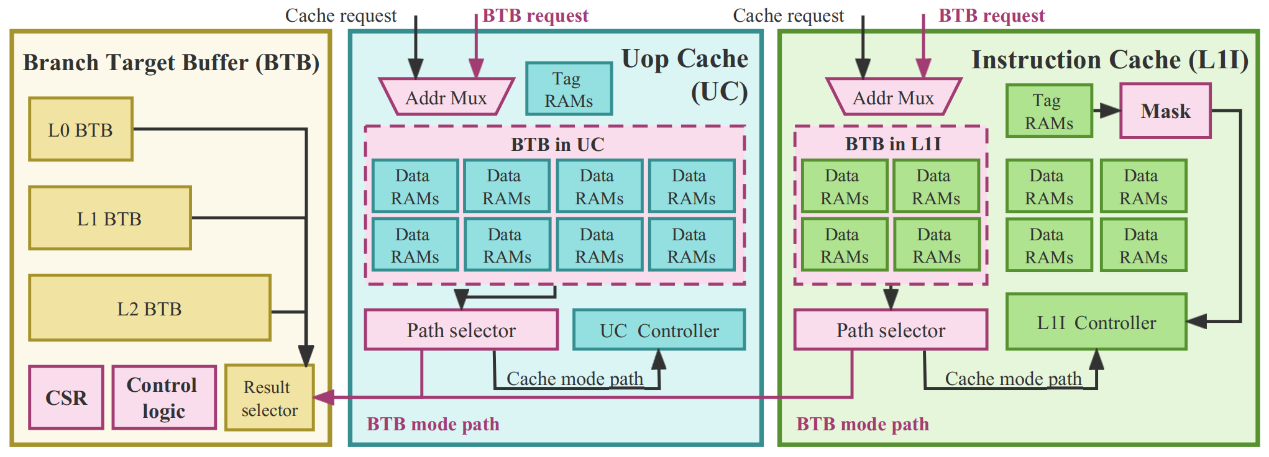
AVM-BTB is an adaptive, virtualized multi-level branch target buffer (BTB) technology. The BTB records the addresses of branch instructions and their corresponding target addresses, allowing the processor to predict the target of a branch instruction prior to execution, thereby mitigating pipeline stalls caused by branch instructions. Additionally, the BTB aids the processor in instruction prefetching, reducing instruction cache (ICache) misses. The proposed AVM-BTB dynamically and adaptively utilizes uop cache and part of the ICache to store BTB entries. This approach significantly mitigates branch prediction errors resulting from BTB misses and enhances instruction prefetching efficiency, especially when the processor contends with workloads characterized by substantial instruction footprints. AVM-BTB enables processors to operate with high performance and low power consumption under varying instruction footprint sizes, without significantly increasing on-chip resource consumption, meeting the increasingly complex computational demands of today.
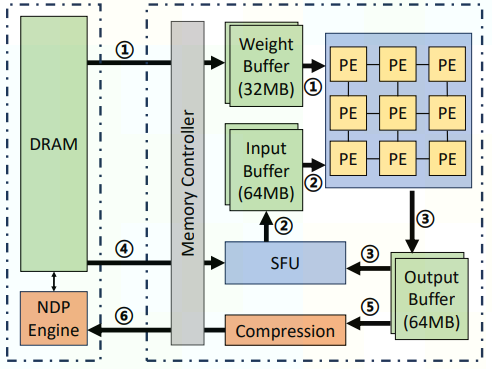
Cambricon-D is the first novel processor design that addresses Diffusion Model acceleration specifically. Diffusion Models have shown superior results in image generation and are widely used (including OpenAI Sora). In the multi-step iterative denoising operation of Diffusion Models, the same model must be repeatedly computed with minimally altered inputs, causing redundancy in its computation. It might appear that performing differential computing with the input data would be an effective method to reduce the computational redundancy, however, the nonlinear operations (especially the activation functions) require that the delta values be repetitively merged with the original input to ensure the correctness of the computation. This repetitive merging introduces a large amount of memory accesses to load the original inputs, canceling the performance gains from the differential computing.
The proposed Cambricon-D architecture utilizes a full-network differential method to mitigate these additional memory accesses, while maintaining the concise computation from differential computing. At the core of the full-network differential method lies a sign-mask dataflow, which only loads the 1-bit sign bits of the original input onto the chip, rather than the large bitwidth original inputs themselves, completing the merging with the delta values. Therefore, while maintaining the correctness of the model and the conciseness of the differential computation, this approach saves a significant amount of memory accesses, finally achieving 5x~10x energy efficiency gains in multiple Diffusion Models.
downloadFile