Recently, researchers from the Institute of Computing Technology (ICT), Chinese Academy of Sciences, alongside collaborative teams, have made a significant breakthrough in the autonomous biomedical scientific data analysis. Combining large language models (LLMs) with multi-agent technology, the research team has successfully developed BioMedAgent, an "AI Data Scientist" computational framework with self-evolving capabilities.
Artificial intelligence agents are emerging as powerful applications of large language models, automating complex tasks and enabling scientific data exploration. However, their use in biomedical data analysis remains limited by the difficulty of handling specialized tools and multistep reasoning. The BioMedAgent framework learns to use diverse bioinformatics tools and chain them into executable workflows through interactive exploration and memory retrieval algorithms. It allows biomedical users to initiate tasks using natural language, without requiring computational expertise.
Evaluated on the newly released BioMed-AQA benchmark comprising 327 biomedical data tasks, BioMedAgent achieved a 77% success rate, surpassing other LLM agents, and generalized robustly to the external BixBench dataset. Beyond benchmarks, it autonomously performs cross-omics analysis, machine-learning modelling, and pathology image segmentation, showcasing substantial real-world utility.
This achievement highlights the potential of artificial intelligence to transition from simple tool assistance to autonomous scientific collaboration, extending to scientific domains requiring complex tool integration and multistep reasoning. This research has been published in the journal Nature Biomedical Engineering. It was supported by the National Key Research and Development Program of China, the National Natural Science Foundation of China, and the Beijing Natural Science Foundation among others.
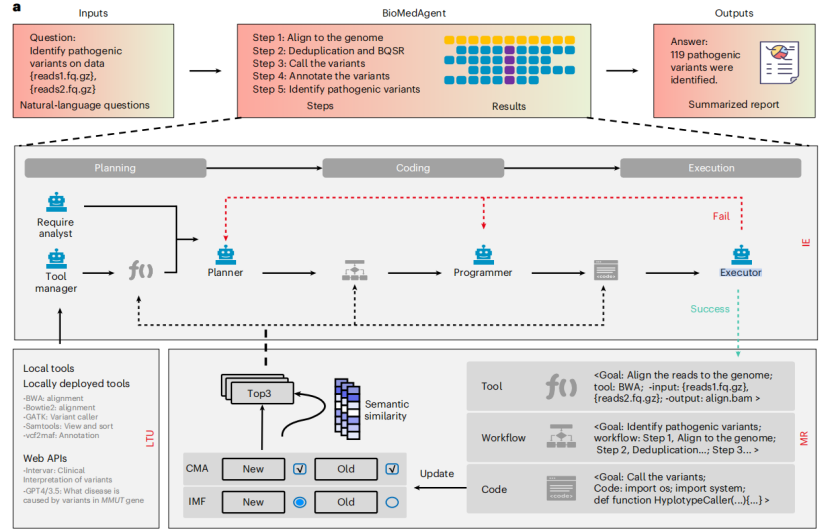
The "AI Data Scientist" computational framework BioMedAgent
downloadFile