Recently, the NeurIPS 2025, the world's most prestigious international academic conference on artificial intelligence, announced its accepted papers. Nine papers from the National Key Laboratory of Intelligent Algorithm Security were selected for publication.
NeurIPS, the Annual Conference on Neural Information Processing Systems, is one of the "three top-tier conferences" in the field of artificial intelligence, alongside ICML and ICLR. It is classified as an A-tier conference in the recommended conference list of the China Computer Federation and rated as A* in the CORE Conference Ranking. With an H5-index exceeding 330, it consistently ranks first in global influence among international academic conferences on artificial intelligence and machine learning.
NeurIPS has seen unprecedented growth in both submission volume and competition intensity. In 2025, the main conference received over 21,575 valid submissions, yet the acceptance rate fell below 24.52%, reflecting its exceptionally high academic standards and difficulty.
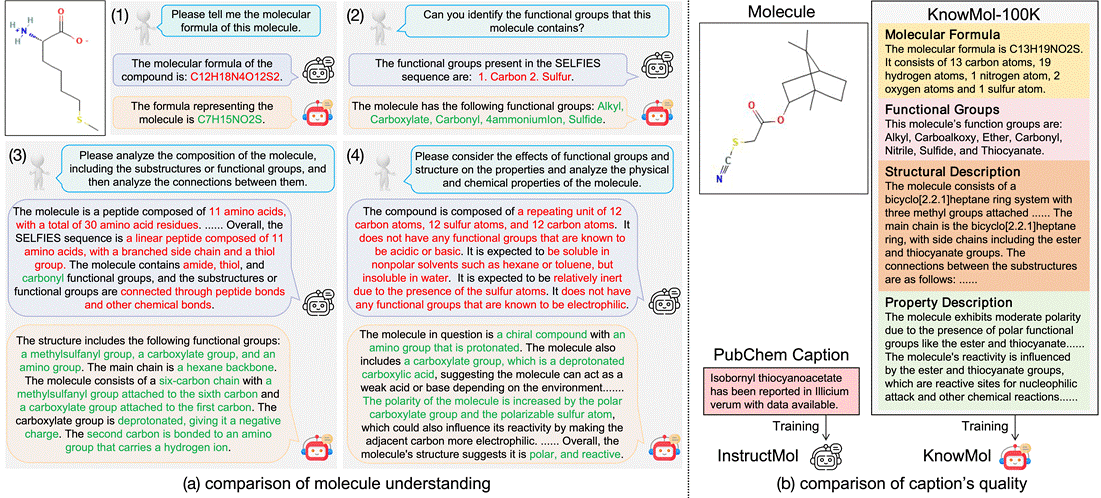
1. KnowMol: Advancing Molecular Large Language Models with Multi-Level Chemical Knowledge
Author: Zaifei Yang, Hong Chang, RuiBing Hou, Shiguang Shan, Xilin Chen
GitHub: https://github.com/yzf-code/KnowMol
Huggingface: https://hf.co/datasets/yzf1102/KnowMol-100K
Abstract: The molecular large language models have garnered widespread attention due to their promising potential on molecular applications. However, current molecular large language models face significant limitations in understanding molecules due to inadequate textual descriptions and suboptimal molecular representation strategies during pretraining. To address these challenges, we introduce KnowMol-100K, a large-scale dataset with 100K fine-grained molecular annotations across multiple levels, bridging the gap between molecules and textual descriptions. Additionally, we propose chemically-informative molecular representation, effectively addressing limitations in existing molecular representation strategies. Building upon these innovations, we develop KnowMol, a state-of-the-art multi-modal molecular large language model. Extensive experiments demonstrate that KnowMol achieves superior performance across molecular understanding and generation tasks.
2. un2CLIP: Improving CLIP's Visual Detail Capturing Ability via Inverting unCLIP
Authors: Yinqi Li, Jiahe Zhao, Hong Chang, Ruibing Hou, Shiguang Shan, Xilin Chen
Code link: https://github.com/LiYinqi/un2CLIP.
Abstract: Contrastive Language-Image Pre-training (CLIP) has become a foundation model and has been applied to various vision and multimodal tasks. However, recent works indicate that CLIP falls short in distinguishing detailed differences in images and shows suboptimal performance on dense-prediction and vision-centric multimodal tasks. Therefore, this work focuses on improving existing CLIP models, aiming to capture as many visual details in images as possible. We find that a specific type of generative models, unCLIP, provides a suitable framework for achieving our goal. Specifically, as illustrated in Figure (a), unCLIP trains an image generator conditioned on the CLIP image embedding. In other words, it inverts the CLIP image encoder. Compared to discriminative models like CLIP, generative models are better at capturing image details because they are trained to learn the data distribution of images. Additionally, the conditional input space of unCLIP aligns with CLIP's original image-text embedding space. Therefore, we propose to invert unCLIP (dubbed un2CLIP) to improve the CLIP model, as illustrated in Figure (c). In this way, the improved image encoder can gain unCLIP's visual detail capturing ability while preserving its alignment with the original text encoder simultaneously. We evaluate our improved CLIP across various tasks to which CLIP has been applied, including the challenging MMVP-VLM benchmark, the dense-prediction open-vocabulary segmentation task, and multimodal large language model tasks. Experiments show that un2CLIP significantly improves the original CLIP and previous CLIP improvement methods.

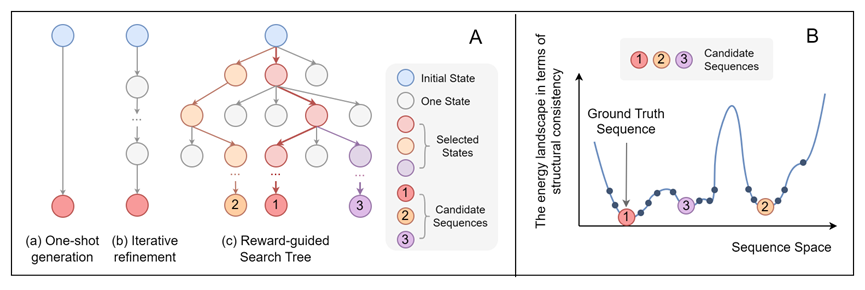
3. ProtInvTree: Deliberate Protein Inverse Folding with Reward-guided Tree Search
Authors: Mengdi Liu, Xiaoxue Cheng, Zhangyang Gao, Hong Chang, Cheng Tan, Shiguang Shan, Xilin Chen
Abstract: Designing protein sequences that fold into a target 3D structure—known as protein inverse folding—is a fundamental challenge in protein engineering. While recent deep learning methods have achieved impressive performance by recovering native sequences, they often overlook the one-to-many nature of the problem: multiple diverse sequences can fold into the same structure. This motivates the need for a generative model capable of designing diverse sequences while preserving structural consistency. To address this trade-off, we introduce ProtInvTree, the first reward-guided tree-search framework for protein inverse folding. ProtInvTree reformulates sequence generation as a deliberate, step-wise decision-making process, enabling the exploration of multiple design paths and exploitation of promising candidates through self-evaluation, lookahead, and backtracking. We propose a two-stage focus-and-grounding action mechanism that decouples position selection and residue generation. To efficiently evaluate intermediate states, we introduce a jumpy denoising strategy that avoids full rollouts. Built upon pretrained protein language models, ProtInvTree supports flexible test-time scaling by expanding the search depth and breadth without retraining. Empirically, ProtInvTree outperforms state-of-the-art baselines across multiple benchmarks, generating structurally consistent yet diverse sequences, including those far from the native ground truth.
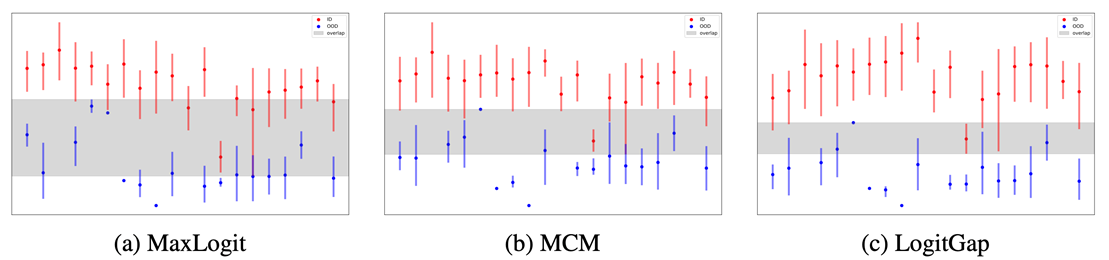
4. Revisiting Logit Distributions for Reliable Out-of-Distribution Detection
Author: Jiachen Liang, Ruibing Hou, Minyang Hu, Hong Chang, Shiguang Shan, Xilin Chen
Abstract: Out-of-distribution (OOD) detection is critical for ensuring the reliability of deep learning models in open-world applications. While post-hoc methods are favored for their efficiency and ease of deployment, existing approaches often underexploit the rich information embedded in the model’s logits space. In this paper, we propose LogitGap, a novel post-hoc OOD detection method that explicitly exploits the relationship between the maximum logit and the remaining logits to enhance the separability between in-distribution (ID) and OOD samples. To further improve its effectiveness, we refine LogitGap by focusing on a more compact and informative subset of the logit space. Specifically, we introduce a training-free strategy that automatically identifies the most informative logits for scoring. We provide both theoretical analysis and empirical evidence to validate the effectiveness of our approach. Extensive experiments on both vision-language and vision-only models demonstrate that LogitGap consistently achieves state-of-the-art performance across diverse OOD detection scenarios and benchmarks.
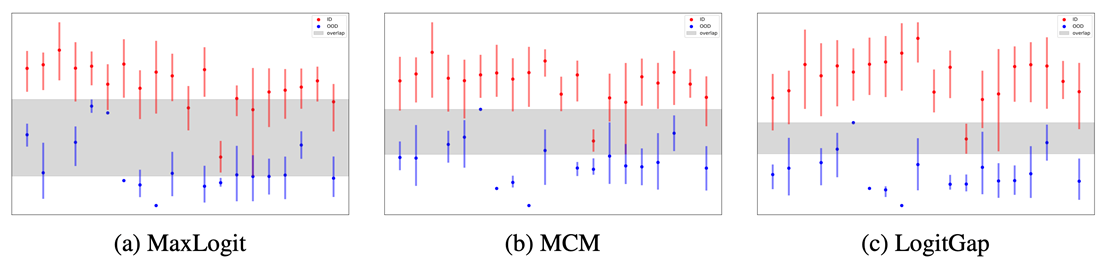
Figure: OOD score distributions for ID and OOD samples across scoring functions.
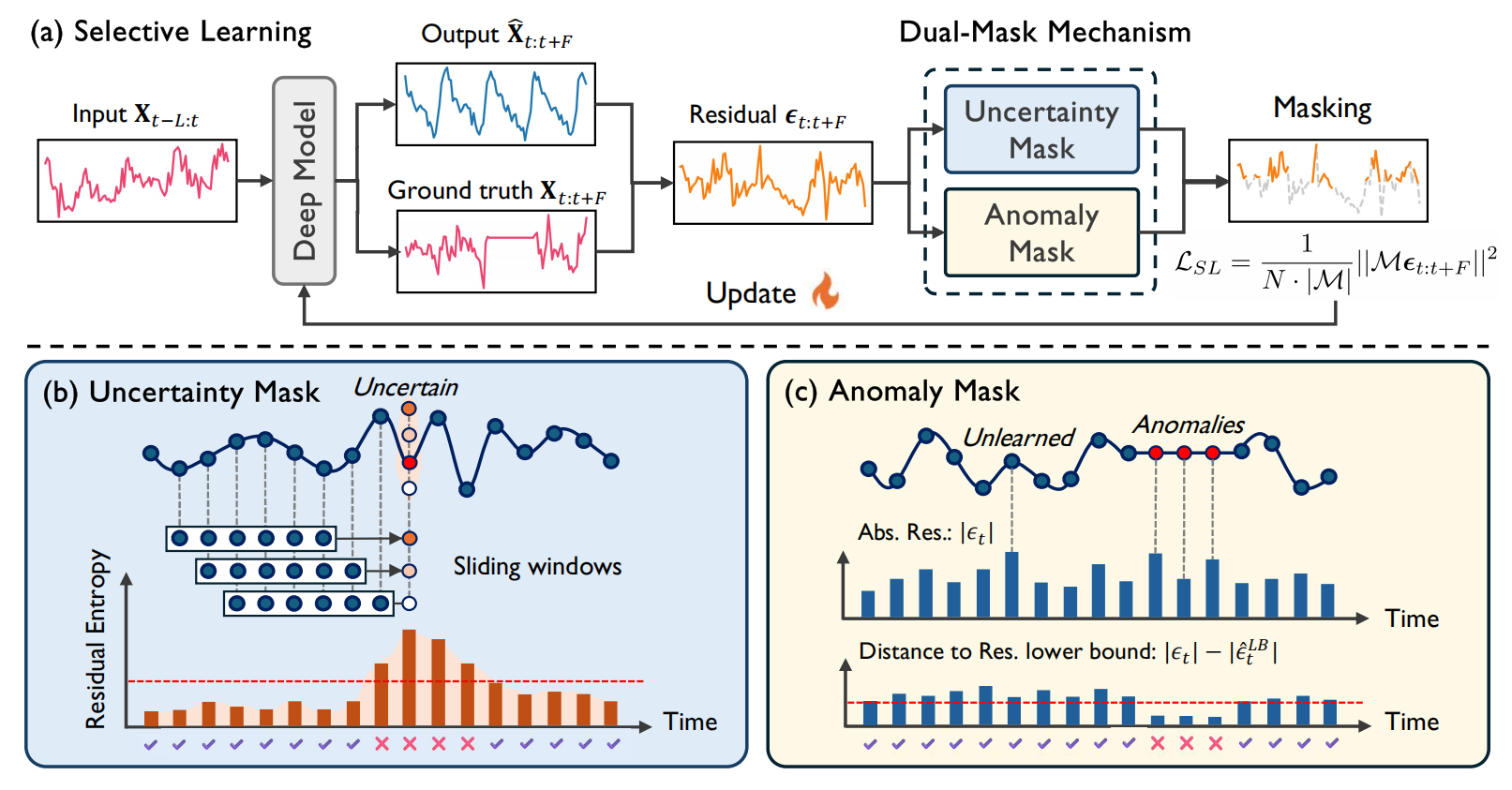
5. Selective Learning for Deep Time Series Forecasting
Author: Yisong Fu, Zezhi Shao, Chengqing Yu, Yujie Li, Zhulin An, Qi (Cheems) Wang, Yongjun Xu, Fei Wang
Code Link: https://github.com/GestaltCogTeam/selective-learning
Abstract:Benefiting from high capacity for capturing complex temporal patterns, deep learning (DL) has significantly advanced time series forecasting (TSF). However, deep models tend to suffer from severe overfitting due to the inherent vulnerability of time series to noise and anomalies. The prevailing DL paradigm uniformly optimizes all timesteps through the MSE loss and learns those uncertain and anomalous timesteps without difference, ultimately resulting in overfitting. To address this, we propose a novel selective learning strategy for deep TSF. Specifically, selective learning screens a subset of the whole timesteps to calculate the MSE loss in optimization, guiding the model to focus on generalizable timesteps while disregarding non-generalizable ones. Our framework introduces a dual-mask mechanism to target timesteps: (1) an uncertainty mask leveraging residual entropy to filter uncertain timesteps, and (2) an anomaly mask employing residual lower bound estimation to exclude anomalous timesteps. Extensive experiments across eight real-world datasets demonstrate that selective learning can significantly improve the predictive performance for typical state-of-the-art deep models, including 37.4% MSE reduction for Informer, 8.4% for TimesNet, and 6.5% for iTransformer.
6. On the Integration of Spatial-Temporal Knowledge: A Lightweight Approach to Atmospheric Time Series Forecasting
Author:Yisong Fu, Fei Wang, Zezhi Shao, Boyu Diao, Lin Wu, Zhulin An, Chengqing Yu, Yujie Li, Yongjun Xu
Code Link: https://github.com/GestaltCogTeam/STELLA
Abstract:Transformers have gained attention in atmospheric time series forecasting (ATSF) for their ability to capture global spatial-temporal correlations. However, their complex architectures lead to excessive parameter counts and extended training times, limiting their scalability to large-scale forecasting. In this paper, we revisit ATSF from a theoretical perspective of atmospheric dynamics and uncover a key insight: spatial-temporal position embedding (STPE) can inherently model spatial-temporal correlations even without attention mechanisms. Its effectiveness arises from integrating geographical coordinates and temporal features, which are intrinsically linked to atmospheric dynamics. Based on this, we propose STELLA, a Spatial-Temporal knowledge Embedded Lightweight modeL for ASTF, utilizing only STPE and an MLP architecture in place of Transformer layers. With 10k parameters and one hour of training, STELLA achieves superior performance on five datasets compared to other advanced methods. The paper emphasizes the effectiveness of spatial-temporal knowledge integration over complex architectures, providing novel insights for ATSF.
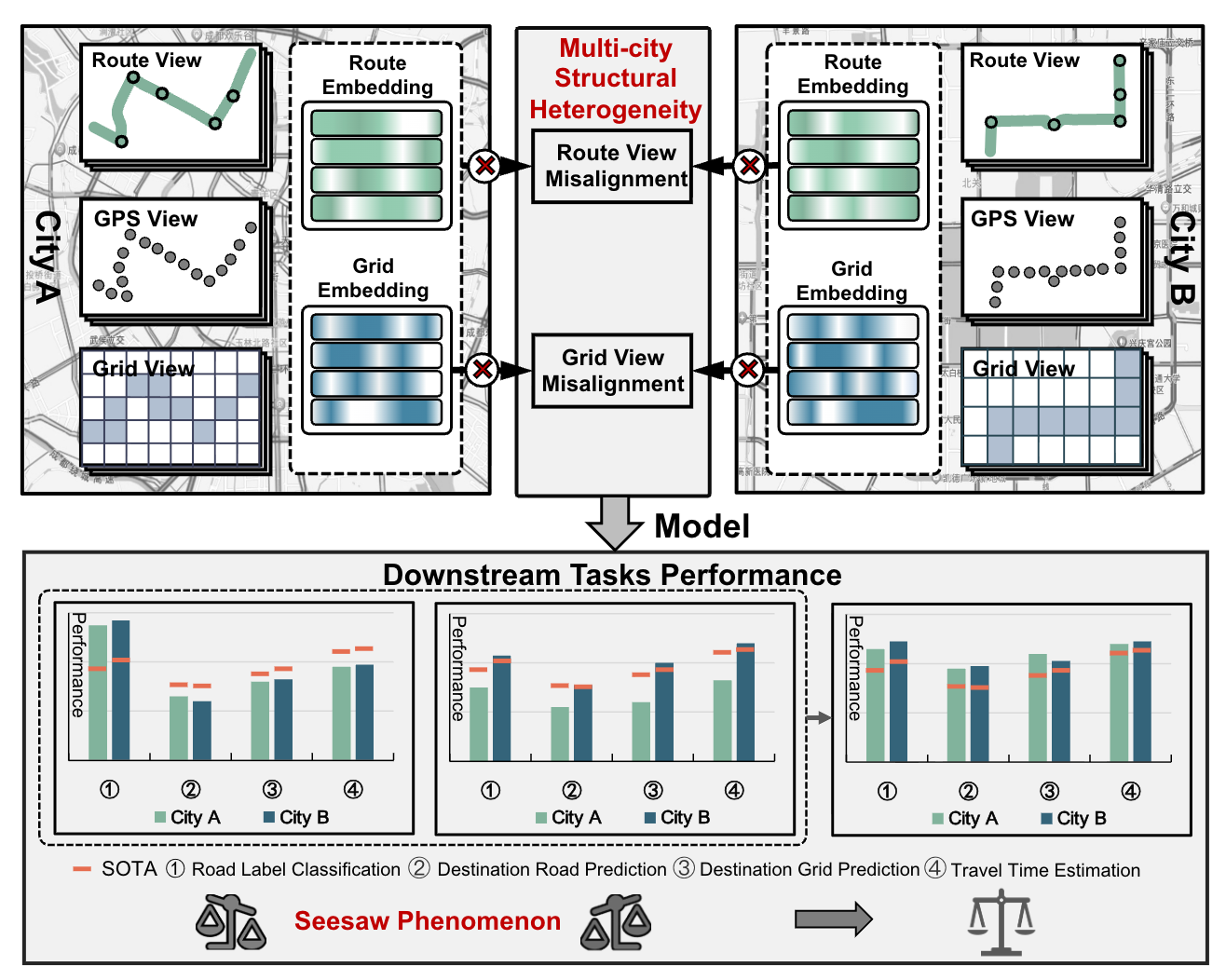
7. SMARTraj2: A Stable Multi-City Adaptive Method for Multi-View Spatio-Temporal Trajectory Representation Learning
Author:Tangwen Qian, Junhe Li, Yile Chen, Gao Cong, Zezhi Shao, Jun Zhang, Tao Sun, Fei Wang, Yongjun Xu
Code Link: https://github.com/GestaltCogTeam/SMARTraj
Abstract:Spatio-temporal trajectory representation learning plays a crucial role in various urban applications such as transportation systems, urban planning, and environmental monitoring. Existing methods can be divided into single-view and multi-view approaches, with the latter offering richer representations by integrating multiple sources of spatio-temporal data. However, these methods often struggle to generalize across diverse urban scenes due to multi-city structural heterogeneity, which arises from the disparities in road networks, grid layouts, and traffic regulations across cities, and the amplified seesaw phenomenon, where optimizing for one city, view, or task can degrade performance in others. These challenges hinder the deployment of trajectory learning models across multiple cities, limiting their real-world applicability. In this work, we propose SMARTraj$^2$, a novel stable multi-city adaptive method for multi-view spatio-temporal trajectory representation learning. Specifically, we introduce a feature disentanglement module to separate domain-invariant and domain-specific features, and a personalized gating mechanism to dynamically stabilize the contributions of different views and tasks. Our approach achieves superior generalization across heterogeneous urban scenes while maintaining robust performance across multiple downstream tasks. Extensive experiments on benchmark datasets demonstrate the effectiveness of SMARTraj$^2$ in enhancing cross-city generalization and outperforming state-of-the-art methods.
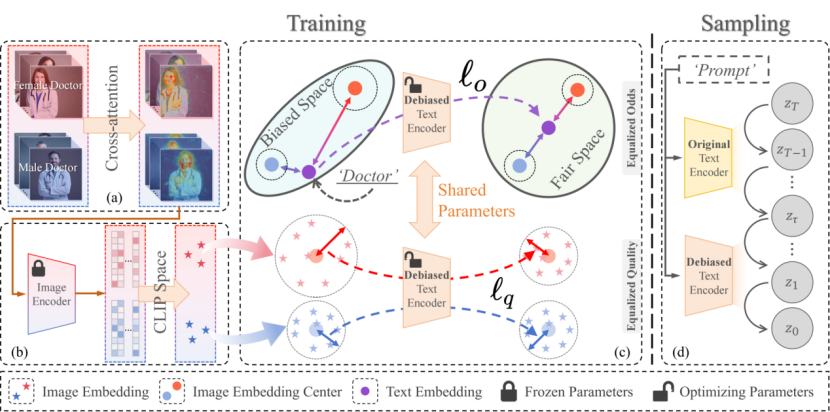
8. LightFair: Towards an Efficient Alternative for Fair T2I Diffusion via Debiasing Pre-trained Text Encoders
LightFair: Towards an Efficient Alternative for Fair T2I Diffusion via Debiasing Pre-trained Text Encoders
Author:Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Kangli Zi, Qingming Huang
Abstract:Current text-to-image diffusion models (T2I DMs) generally suffer from imbalanced output distributions and latent biases. This paper explores a novel lightweight approach LightFair to achieve fair T2I DMs by addressing the adverse effects of the text encoder. Most existing methods either couple different parts of the diffusion model for full-parameter training or rely on auxiliary networks for correction. They incur heavy training or sampling burden and unsatisfactory performance. Since T2I DMs consist of multiple components, with the text encoder being the most fine-tunable and front-end module, this paper focuses on mitigating bias by fine-tuning text embeddings. To validate feasibility, we observe that the text encoder’s neutral embedding output shows substantial skewness across image embeddings of various attributes in the CLIP space. More importantly, the noise prediction network further amplifies this imbalance. To finetune the text embedding, we propose a collaborative distance-constrained debiasing strategy that balances embedding distances to improve fairness without auxiliary references. However, mitigating bias can compromise the original generation quality. To address this, we introduce a two-stage text-guided sampling strategy to limit when the debiased text encoder intervenes. Extensive experiments demonstrate that LightFair is effective and efficient. Notably, on Stable Diffusion v1.5, our method achieves SOTA debiasing at just 1/4 of the training burden, with virtually no increase in sampling burden.
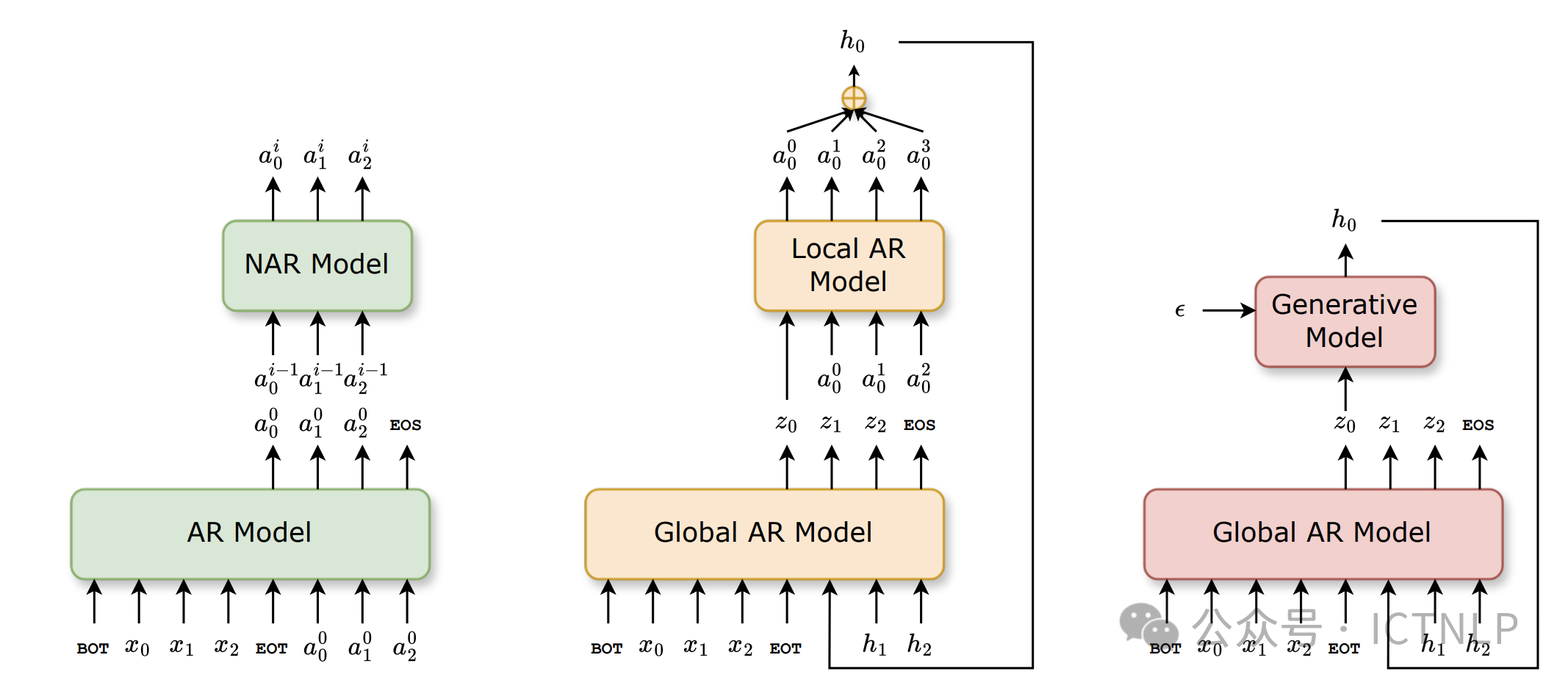
9. Efficient Speech Language Modeling via Energy Distance in Continuous Latent Space
Author:Zhengrui Ma, Yang Feng, Chenze Shao, Fandong Meng, Jie Zhou, Min Zhang
Abstract:We introduce SLED, an alternative approach to speech language modeling by encoding speech waveforms into sequences of continuous latent representations and modeling them autoregressively using an energy distance objective. The energy distance offers an analytical measure of the distributional gap by contrasting simulated and target samples, enabling efficient training to capture the underlying continuous autoregressive distribution. By bypassing reliance on residual vector quantization, SLED avoids discretization errors and eliminates the need for the complicated hierarchical architectures common in existing speech language models. It simplifies the overall modeling pipeline while preserving the richness of speech information and maintaining inference efficiency. Empirical results demonstrate that SLED achieves strong performance in both zero-shot and streaming speech synthesis, showing its potential for broader applications in general-purpose speech language models.
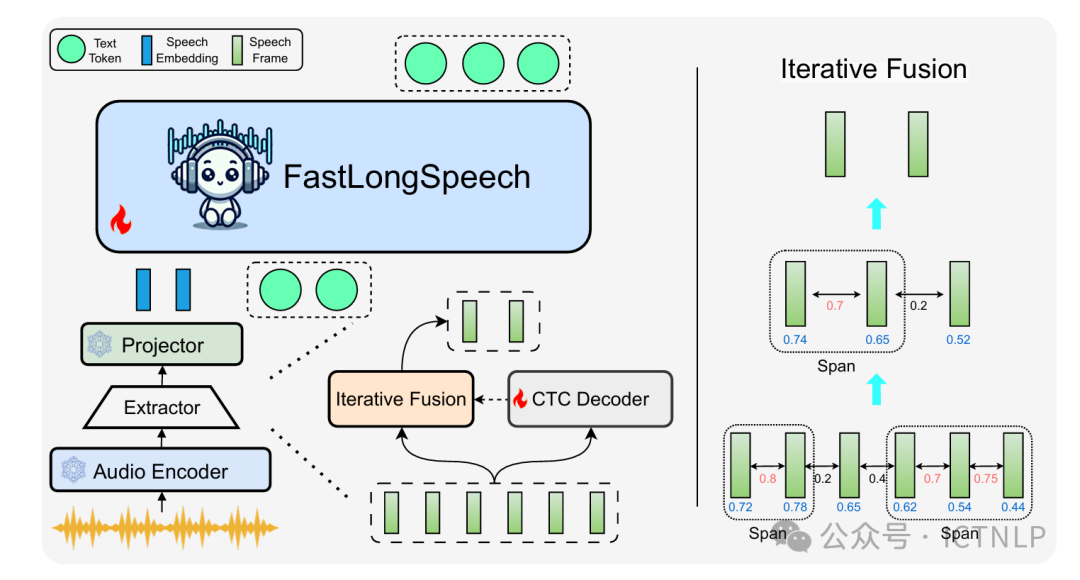
10. FastLongSpeech: Enhancing Large Speech-Language Models for Efficient Long-Speech Processing
Author:Shoutao Guo, Shaolei Zhang, Qingkai Fang, Zhengrui Ma, Min Zhang, Yang Feng
Abstract:The rapid advancement of Large Language Models (LLMs) has spurred significant progress in Large Speech-Language Models (LSLMs), enhancing their capabilities in both speech understanding and generation. While existing LSLMs often concentrate on augmenting speech generation or tackling a diverse array of short-speech tasks, the efficient processing of long-form speech remains a critical yet underexplored challenge. This gap is primarily attributed to the scarcity of long-speech training datasets and the high computational costs associated with long sequences. To address these limitations, we introduce FastLongSpeech, a novel framework designed to extend LSLM capabilities for efficient long-speech processing without necessitating dedicated long-speech training data. FastLongSpeech incorporates an iterative fusion strategy that can compress excessively long-speech sequences into manageable lengths. To adapt LSLMs for long-speech inputs, it introduces a dynamic compression training approach, which exposes the model to short-speech sequences at varying compression ratios, thereby transferring the capabilities of LSLMs to long-speech tasks. To assess the long-speech capabilities of LSLMs, we develop a long-speech understanding benchmark called LongSpeech-Eval. Experiments show that our method exhibits strong performance in both long-speech and short-speech tasks, while greatly improving inference efficiency.
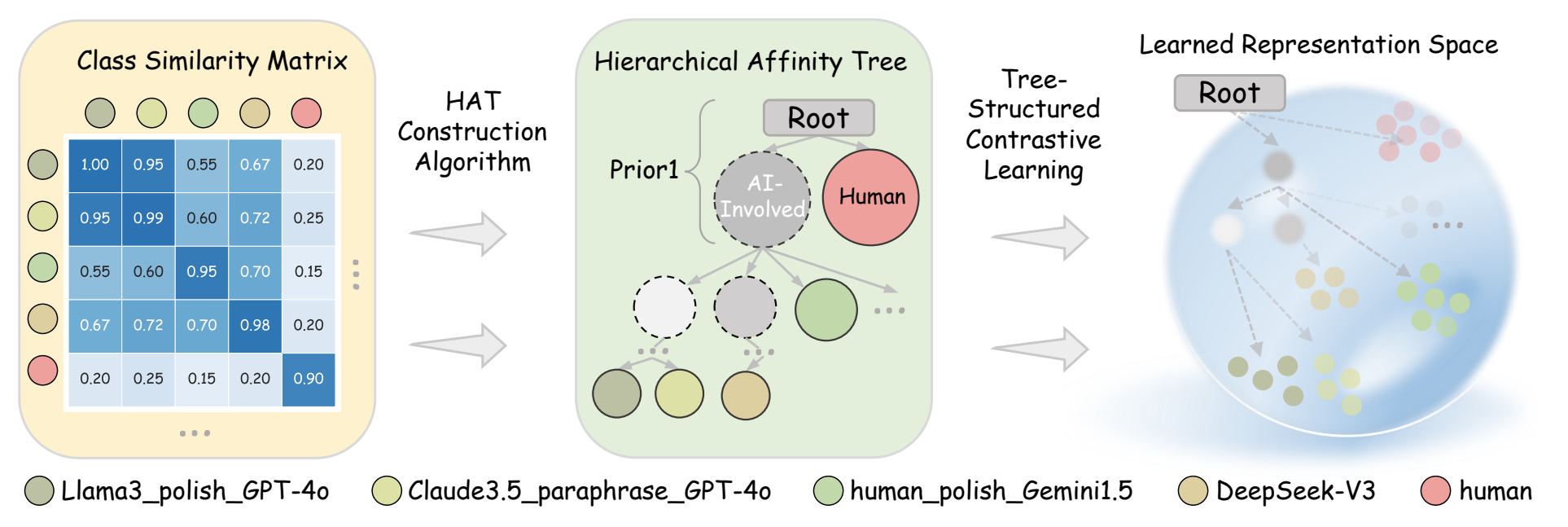
11.DETree:DEtecting Human-AI Collaborative Texts via Tree-Structured Hierarchical Representation Learning
Author:Yongxin He, Shan Zhang, Yixuan Cao, Lei Ma, Ping Luo
Code Link: https://github.com/heyongxin233/DETree
Abstract:Detecting AI-involved text is essential for combating misinformation, plagiarism, and academic misconduct. However, AI text generation includes diverse collaborative processes (AI-written text edited by humans, human-written text edited by AI, and AI-generated text refined by other AI), where various or even new LLMs could be involved. Texts generated through these varied processes exhibit complex characteristics, presenting significant challenges for detection. Current methods model these processes rather crudely, primarily employing binary classification (purely human vs. AI-involved) or multi-classification (treating human-AI collaboration as a new class). We observe that representations of texts generated through different processes exhibit inherent clustering relationships. So, we propose DETree, a novel approach that models the relationships among different processes as a Hierarchical Affinity Tree structure, and introduces a specialized loss function that aligns representations to this tree. To facilitate this learning, we developed RealBench, a comprehensive benchmark dataset that automatically incorporates a wide spectrum of hybrid texts produced through various human-AI collaboration processes. Our method improves performance in hybrid text detection tasks and significantly enhances robustness and generalization in out-of-distribution scenarios, particularly in few-shot learning conditions, further demonstrating the promise of training-based approaches in OOD settings.
downloadFile