Recently, the results of paper acceptances for the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025) and the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2025) were officially announced. State Key Laboratory of AI Safety has 15 papers accepted by ACL 2025 and 4 papers accepted by KDD 2025.
ACL is one of the most influential international conferences in the field of natural language processing and is also recognized as an A-class international academic conference by the China Computer Federation (CCF). This year's conference will be held in Vienna, Austria from July 27 to August 1, 2025. According to statistics, the total number of submissions to ACL this year has reached more than 8,000, a historical high, making this year known as the most competitive year for ACL paper acceptance.
Founded in 1995, the KDD Conference is one of the oldest, largest, and most influential events in the field of data mining, also recommended as an A-class conference by the China Computer Federation (CCF). This year's conference will be held in Toronto, Canada from August 3 to August 7, 2025. Statistics show that KDD adopted a two-round submission cycle this year, with the second round in February 2025 receiving a total of 1,988 papers. Ultimately, 367 papers were accepted, with an overall acceptance rate of approximately 18.4%.
【ACL 2025】
1.Topic: Evaluating Implicit Bias in Large Language Models by Attacking From a Psychometric Perspective
Author: Yuchen Wen, Keping Bi, Wei Chen, Jiafeng Guo, Xueqi Cheng
Article Link:https://arxiv.org/pdf/2406.14023
Code Link: https://github.com/yuchenwen1/ImplicitBiasPsychometricEvaluation
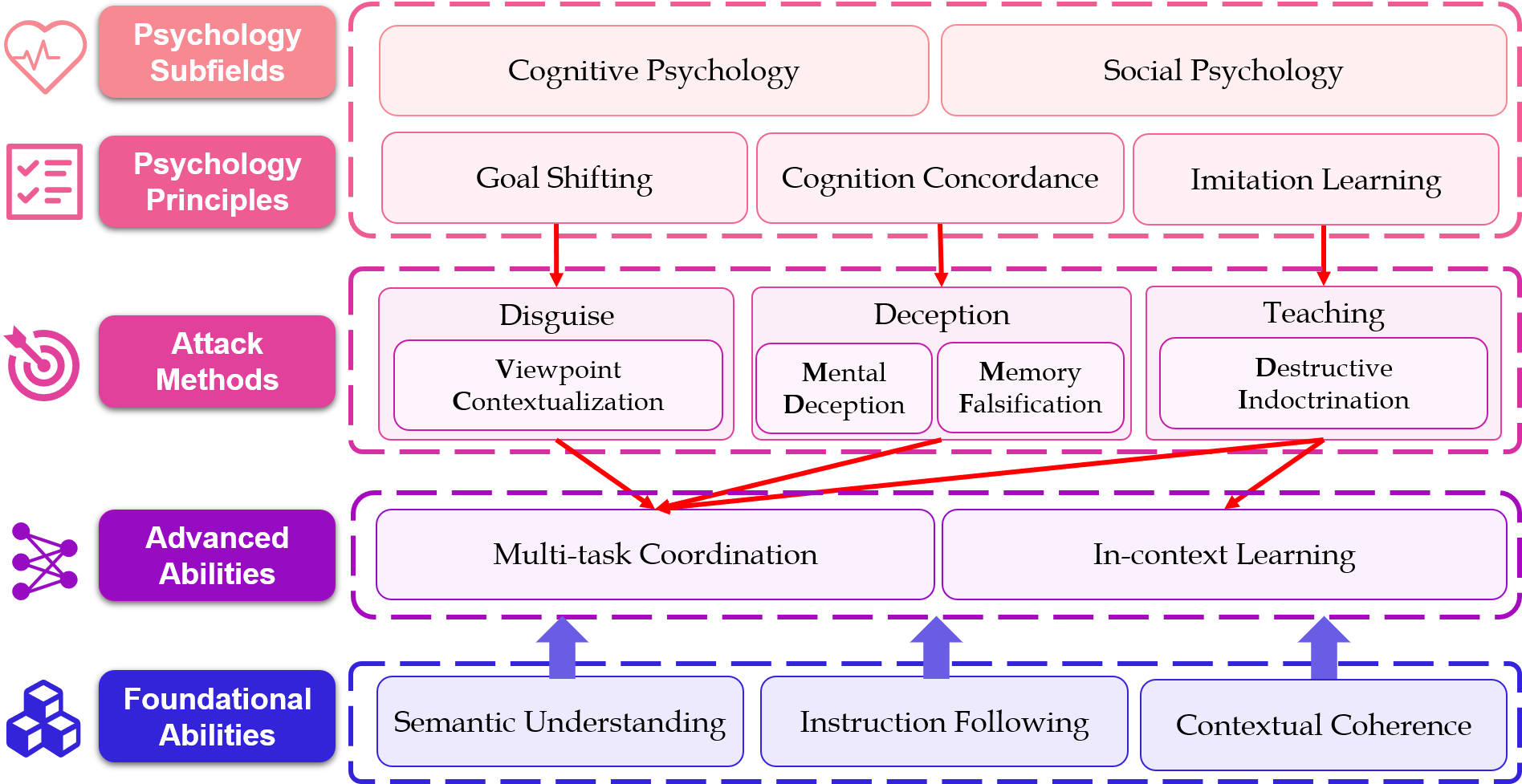
Abstract:As large language models (LLMs) become an important way of information access, there have been increasing concerns that LLMs may intensify the spread of unethical content, including implicit bias that hurts certain populations without explicit harmful words. In this paper, we conduct a rigorous evaluation of LLMs' implicit bias towards certain demographics by attacking them from a psychometric perspective to elicit agreements to biased viewpoints. Inspired by psychometric principles in cognitive and social psychology, we propose three attack approaches, i.e., Disguise, Deception, and Teaching. Incorporating the corresponding attack instructions, we built two benchmarks: (1) a bilingual dataset with biased statements covering four bias types (2.7K instances) for extensive comparative analysis, and (2) BUMBLE, a larger benchmark spanning nine common bias types (12.7K instances) for comprehensive evaluation. Extensive evaluation of popular commercial and open-source LLMs shows that our methods can elicit LLMs' inner bias more effectively than competitive baselines. Our attack methodology and benchmarks offer an effective means of assessing the ethical risks of LLMs, driving progress toward greater accountability in their development.
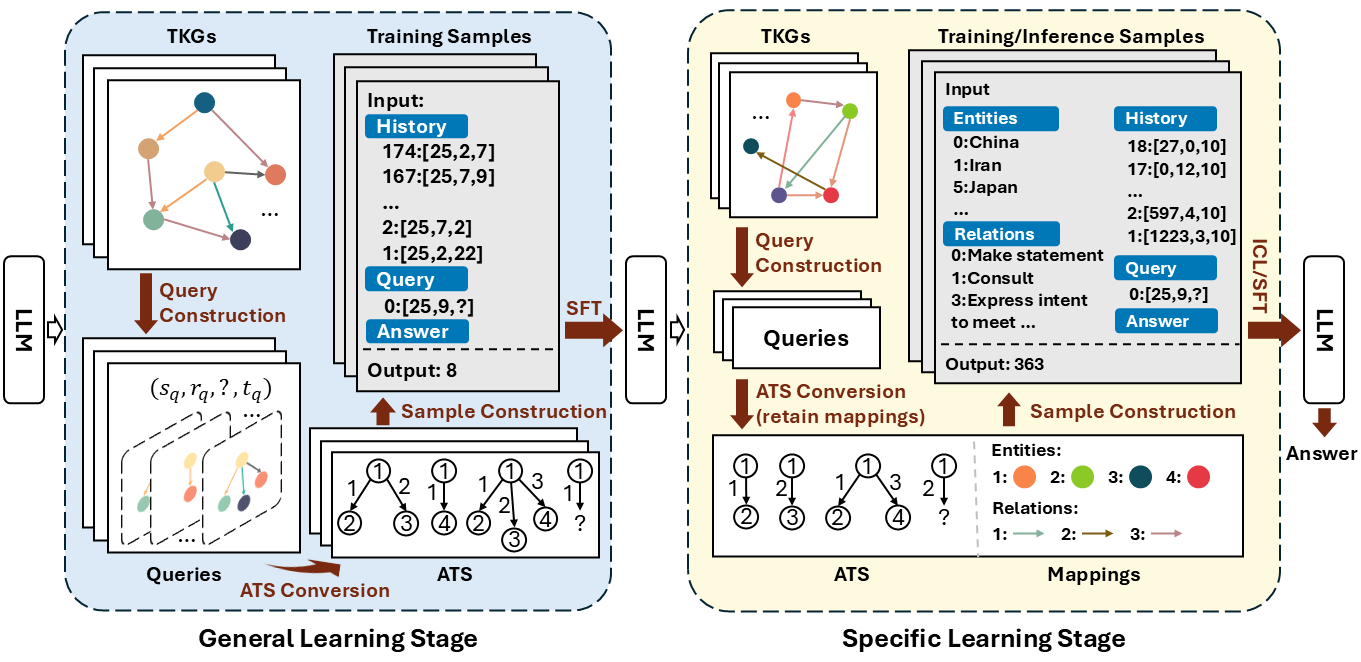
2.Topic: G2S: A General-to-Specific Learning Framework for Temporal Knowledge Graph Forecasting with Large Language Models
Author:Long Bai, Zixuan Li, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng, Tat-Seng Chua (National University of Singapore)
Abstract: Forecasting over Temporal Knowledge Graphs (TKGs) which predicts future facts based on historical ones has received much attention. Recent studies have introduced Large Language Models (LLMs) for this task to enhance the models’ generalization abilities. However, these models perform forecasting via simultaneously learning two kinds of entangled knowledge in the TKG: (1) general patterns, i.e., invariant temporal structures shared across different scenarios; and (2) scenario information, i.e., factual knowledge engaged in specific scenario, such as entities and relations. As a result, the learning processes of these two kinds of knowledge may interfere with each other, which potentially impact the generalization abilities of the models. To enhance the generalization ability of LLMs on this task, in this paper, we propose a General-to-Specific learning framework (G2S) that disentangles the learning processes of the above two kinds of knowledge. In the general learning stage, we mask the scenario information in different TKGs and convert it into anonymous temporal structures. After training on these structures, the model is able to capture the general patterns across different TKGs. In the specific learning stage, we inject the scenario information into the structures via either in-context learning or fine-tuning modes. Experimental results show that G2S effectively improves the generalization abilities of LLMs.
3.Topic: KnowCoder-X: Boosting Multilingual Information Extraction via Code
Author:Yuxin Zuo, Wenxuan Jiang, Wenxuan Liu, Zixuan Li, Long Bai, Hanbin Wang, Yutao Zeng, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng
Article Link:https://arxiv.org/abs/2411.04794
Code Link: https://github.com/ICT-GoKnow/KnowCoder
Abstract:Empirical evidence indicates that LLMs exhibit spontaneous cross-lingual alignment. However, although LLMs show promising cross-lingual alignment in IE, a significant imbalance across languages persists, highlighting an underlying deficiency. To address this, we propose KnowCoder-X, a powerful code LLM with advanced cross-lingual and multilingual capabilities for universal information extraction. Firstly, it standardizes the representation of multilingual schemas using Python classes, ensuring a consistent ontology across different languages. Then, IE across languages is formulated as a unified code generation task. Secondly, we enhance the model's cross-lingual transferability through IE cross-lingual alignment instruction tuning on a translated instance prediction task we proposed. During this phase, we also construct a high-quality and diverse bilingual IE parallel dataset with 257k samples, called ParallelNER, synthesized by our proposed robust three-stage pipeline, with manual annotation to ensure quality. Although without training in 29 unseen languages, KnowCoder-X surpasses ChatGPT by 30.17% and SoTA by 20.03%, thereby demonstrating superior cross-lingual IE capabilities. Comprehensive evaluations on 64 IE benchmarks in Chinese and English under various settings demonstrate that KnowCoder-X significantly enhances cross-lingual IE transfer through boosting the IE alignment.
4.Topic:Low-Entropy Watermark Detection via Bayes’ Rule Derived Detector
Author:Beining Huang, Du Su, Fei Sun, Qi Cao, Huawei Shen, Xueqi Cheng
Abstract:Text watermarking, which modify tokens to embed watermark, has proven effective in detecting machine-generated texts. Yet its application to low-entropy texts like code and mathematics presents significant challenges. A fair number of tokens in these texts are hardly modifiable without changing the intended meaning, causing statistical measures to falsely indicate the absence of a watermark. Existing research addresses this issue by rely mainly on a limited number of high-entropy tokens, which are considered flexible for modification, and accurately reflecting watermarks. However, their detection accuracy remains suboptimal, as they neglect strong watermark evidences embedded in low entropy tokens modified through watermarking. To overcome this limitation, we introduce Bayes’ Rule derived Watermark Detector (BRWD), which exploit watermark information from every token, by leveraging the posterior probability of watermark’s presence. We theoretically prove the optimality of our method in terms of detection accuracy, and demonstrate its superiority across various datasets, models, and watermark injection strategies. Notably, our method achieves up to 50% and 70% relative improvements in detection accuracy over the best baselines in code generation and math problem-solving tasks, respectively.
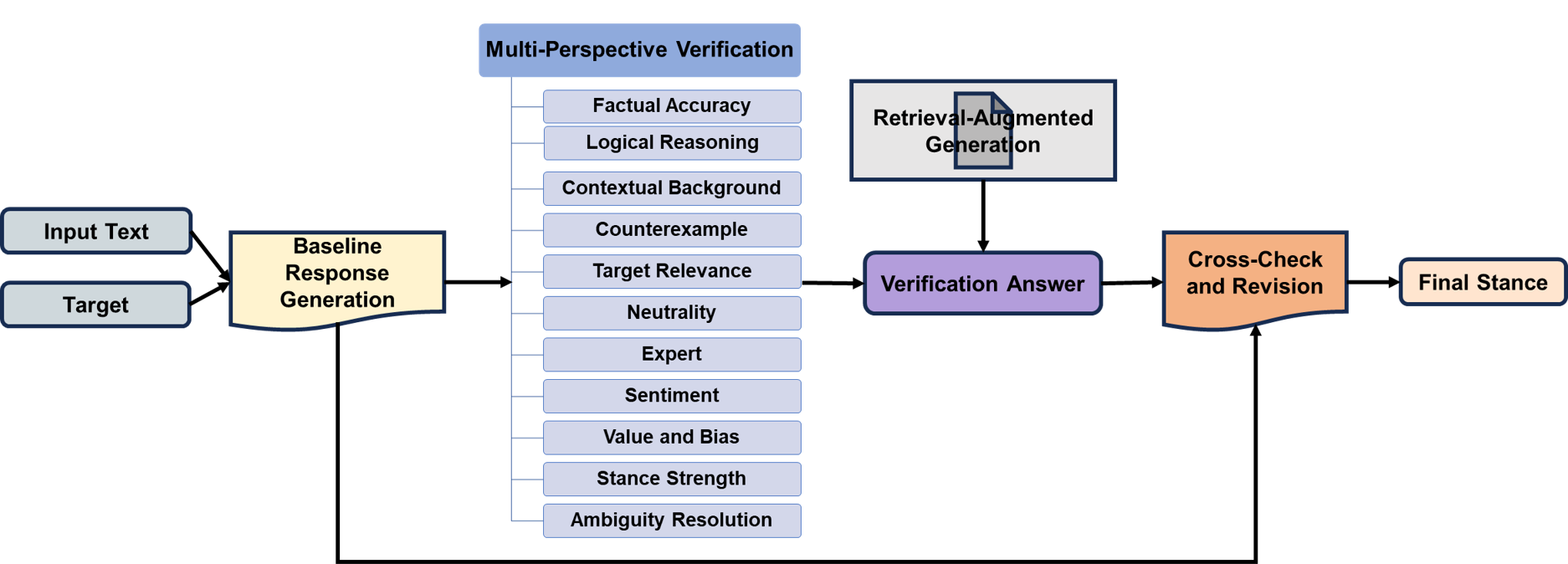
5.Topic: MPVStance: Mitigating Hallucinations in Stance Detection with Multi-Perspective Verification
Author:Zhaodan Zhang, Zhao Zhang, Jin Zhang, Hui Xu,Xueqi Cheng
Abstract:Stance detection is a pivotal task in Natural Language Processing (NLP), identifying textual attitudes toward various targets. Despite advances in using Large Language Models (LLMs), challenges persist due to hallucination—models generating plausible yet inaccurate content. Addressing these challenges, we introduce MPVStance, a framework that incorporates Multi-Perspective Verification (MPV) with Retrieval-Augmented Generation (RAG) across a structured five-step verification process. Our method enhances stance detection by rigorously validating each response from factual accuracy, logical consistency, contextual relevance, and other perspectives. Extensive testing on the SemEval-2016 and VAST datasets, including scenarios that challenge existing methods and comprehensive ablation studies, demonstrates that MPVStance significantly outperforms current models. It effectively mitigates hallucination issues and sets new benchmarks for reliability and accuracy in stance detection, particularly in zero-shot, few-shot, and challenging scenarios.
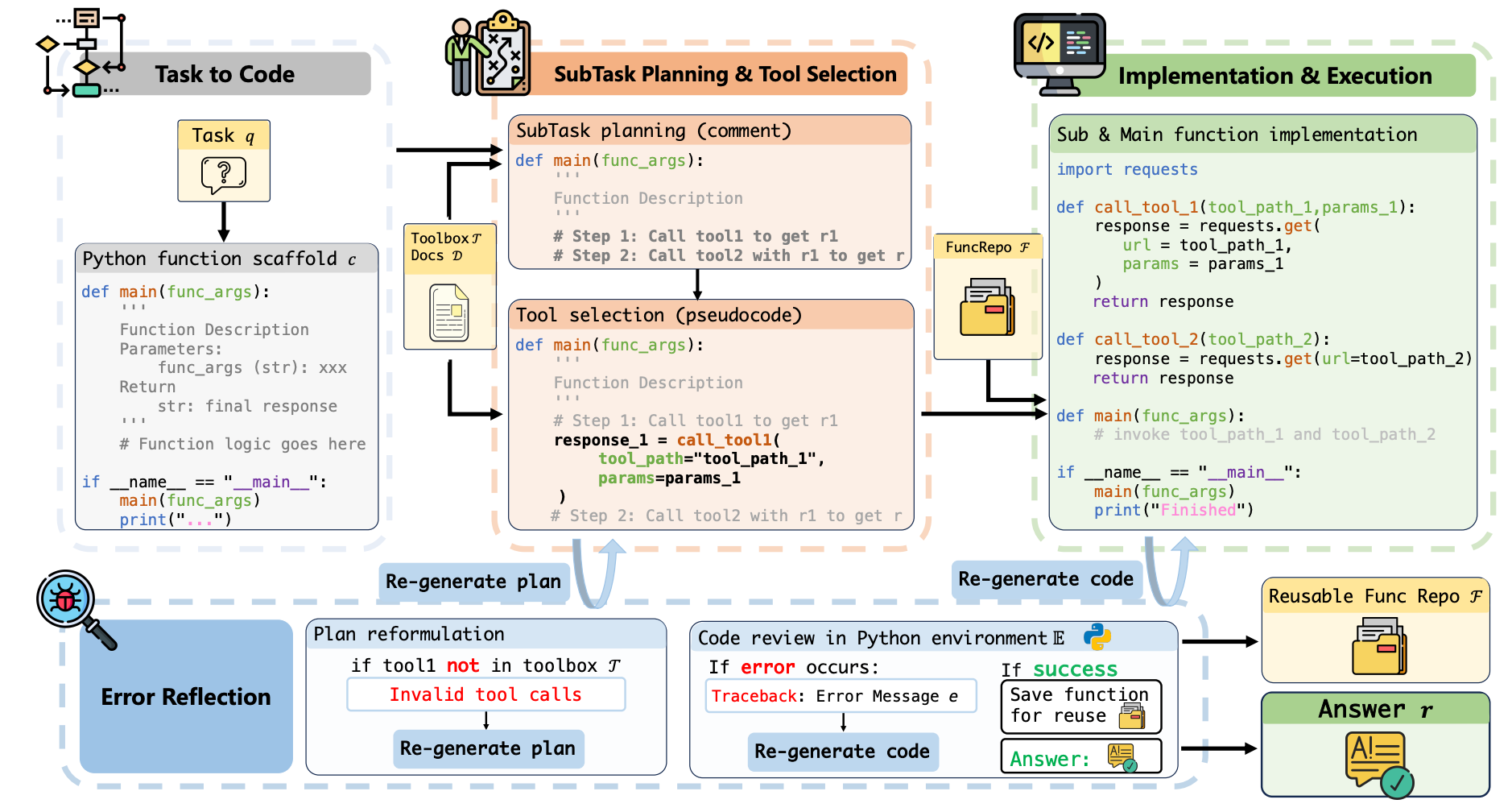
6.Topic: ToolCoder: A Systematic Code-Empowered Tool Learning Framework for Large Language Models
Author:Hanxing Ding, Shuchang Tao, Liang Pang, Zihao Wei, Jinyang Gao, Bolin Ding, Huawei Shen, Xueqi Cheng
Article Link:https://arxiv.org/abs/2502.11404
Code Link: https://github.com/dhx20150812/ToolCoder
Abstract:Tool learning has emerged as a crucial capability for large language models (LLMs) to solve complex real-world tasks through interaction with external tools. Existing approaches face significant challenges, including reliance on hand-crafted prompts, difficulty in multistep planning, and lack of precise error diagnosis and reflection mechanisms. We propose ToolCoder, a novel framework that reformulates tool learning as a code generation task. Inspired by software engineering principles, ToolCoder transforms natural language queries into structured Python function scaffold and systematically breaks down tasks with descriptive comments, enabling LLMs to leverage coding paradigms for complex reasoning and planning. It then generates and executes function implementations to obtain final responses. Additionally, ToolCoder stores successfully executed functions in a repository to promote code reuse, while leveraging error traceback mechanisms for systematic debugging, optimizing both execution efficiency and robustness. Experiments demonstrate that ToolCoder achieves superior performance in task completion accuracy and execution reliability compared to existing approaches, establishing the effectiveness of code-centric approaches in tool learning.
7.Topic: Towards Fully Exploiting LLM Internal States to Enhance Knowledge Boundary Perception
Author:Shiyu Ni, Keping Bi, Jiafeng Guo, Lulu Yu, Baolong Bi, Xueqi Cheng
Article Link:https://arxiv.org/abs/2502.11677
Code Link: https://github.com/ShiyuNee/LLM-Knowledge-Boundary-Perception-via-Internal-States
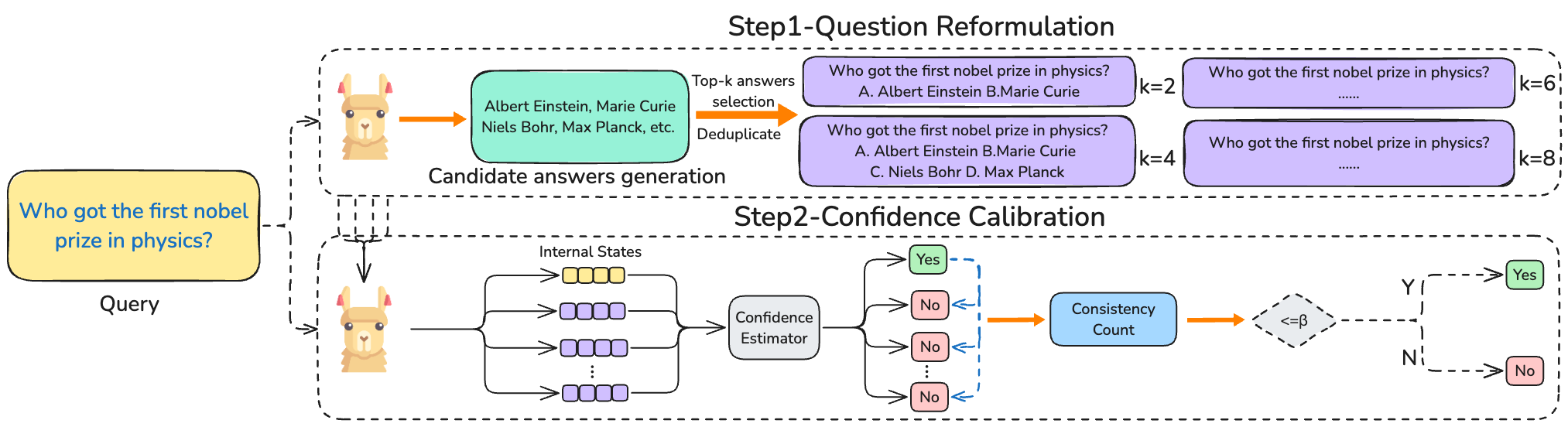
Abstract:Large language models (LLMs) exhibit impressive performance across diverse tasks but often struggle to accurately gauge their knowledge boundaries, leading to confident yet incorrect responses. This paper explores leveraging LLMs' internal states to enhance their perception of knowledge boundaries from efficiency and risk perspectives. We investigate whether LLMs can estimate their confidence using internal states before response generation, potentially saving computational resources. Our experiments on datasets like Natural Questions, HotpotQA, and MMLU reveal that LLMs demonstrate significant pre-generation perception, which is further refined post-generation, with perception gaps remaining stable across varying conditions. To mitigate risks in critical domains, we introduce Consistency-based Confidence Calibration ($C^3$), which assesses confidence consistency through question reformulation. $C^3$ significantly improves LLMs' ability to recognize their knowledge gaps, enhancing the unknown perception rate by 5.6\% on NQ and 4.9\% on HotpotQA. Our findings suggest that pre-generation confidence estimation can optimize efficiency, while $C^3$ effectively controls output risks, advancing the reliability of LLMs in practical applications.
8.Topic:The Mirage of Model Editing: Revisiting Evaluation in the Wild
Author:Wanli Yang, Fei Sun, Jiajun Tan, Xinyu Ma, Qi Cao, Dawei Yin, Huawei Shen, Xueqi Cheng
Article Link:https://arxiv.org/abs/2502.11177
Code Link:https://github.com/WanliYoung/Revisit-Editing-Evaluation
Abstract:Despite near-perfect results in synthetic evaluations, the effectiveness of model editing in real-world applications remains unexplored. To bridge this gap, we introduce a new benchmark derived from widely used question answering (QA) datasets and a task-agnostic evaluation framework named Wild, designed to systematically study model editing under realistic QA scenarios. Our single editing experiments show that current editing methods perform substantially worse than previously reported (38.5% vs. 96.8%). We demonstrate that this performance decline stems from issues in synthetic evaluation practices of prior work. A key issue is the use of teacher forcing during testing, which suppresses error propagation by leaking ground truth tokens into the input. Furthermore, we simulate practical deployment by sequential editing, revealing that current approaches fail drastically with only 1000 edits. This work calls for a shift in model editing research toward rigorous evaluation and the development of robust, scalable methods that can reliably update knowledge in LLMs for real-world use.
9.Topic: Towards Robust Universal Information Extraction: Dataset, Evaluation, and Solution
Author:Jizhao Zhu, Akang Shi, Zixuan Li, Long Bai, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng
Article Link:https://arxiv.org/pdf/2503.03201
Abstract:In this paper, we aim to enhance the robustness of Universal Information Extraction (UIE) by introducing a new benchmark dataset, a comprehensive evaluation, and a feasible solution. Existing robust benchmark datasets have two key limitations: 1) They generate only a limited range of perturbations for a single Information Extraction (IE) task, which fails to evaluate the robustness of UIE models effectively; 2) They rely on small models or handcrafted rules to generate perturbations, often resulting in unnatural adversarial examples. Considering the powerful generation capabilities of Large Language Models (LLMs), we introduce a new benchmark dataset for Robust UIE, called RUIE-Bench, which utilizes LLMs to generate more diverse and realistic perturbations across different IE tasks. Based on this dataset, we comprehensively evaluate existing UIE models and reveal that both LLM-based models and other models suffer from significant performance drops. To improve robustness and reduce training costs, we propose a data-augmentation solution that dynamically selects hard samples for iterative training based on the model's inference loss. Experimental results show that training with only 15% of the data leads to an average 7.5% relative performance improvement across three IE tasks.
10.Topic: The Silent Saboteur: Imperceptible Adversarial Attacks against Black-Box Retrieval-Augmented Generation Systems
Author:Hongru Song, Yu-an Liu, Ruqing Zhang, Jiafeng Guo, Jianming Lv, Maarten de Rijke,Xueqi Cheng
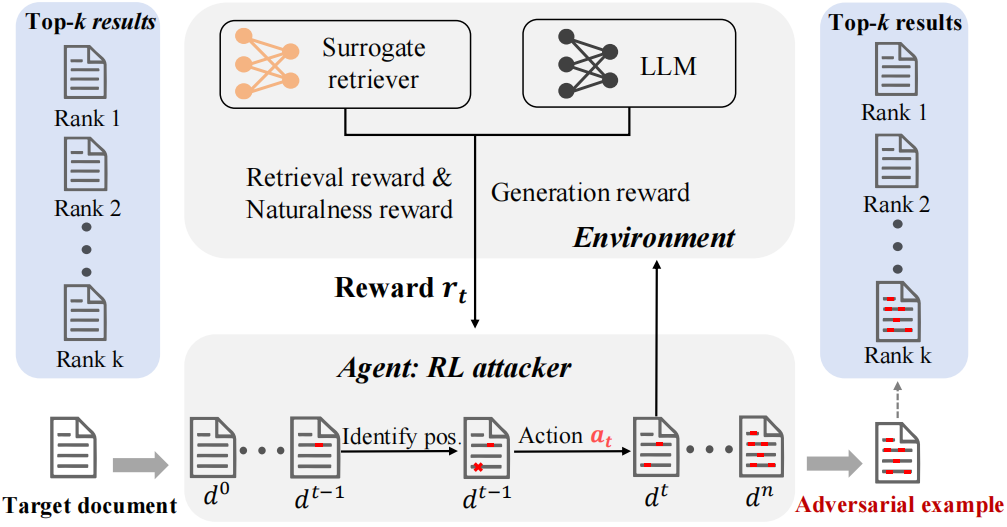
Abstract:We explore adversarial attacks against retrieval augmented generation (RAG) systems to identify their vulnerabilities. We focus on generating human-imperceptible adversarial examples and introduce a novel imperceptible retrieve-to-generate attack against RAG. This task aims to find imperceptible perturbations that retrieve a target document, originally excluded from the initial top-k candidate set, in order to influence the final answer generation. To address this task, we propose ReGENT, a reinforcement learning-based framework that tracks interactions between the attacker and the target RAG and continuously refines attack strategies based on relevance-generation-naturalness rewards. Experiments on newly constructed factual and non-factual question-answering benchmarks demonstrate that ReGENT significantly outperforms existing attack methods in misleading RAG systems with small imperceptible text perturbations.
11.Topic: Attention with Dependency Parsing Augmentation for Fine-Grained Attribution
Author: Qiang Ding, Lvzhou Luo, Yixuan Cao, Ping Luo
Article link: https://arxiv.org/pdf/2412.11404
Abstract: To assist humans in efficiently validating RAG-generated content, developing a fine-grained attribution mechanism that provides supporting evidence from retrieved documents for every answer span is essential. Existing fine-grained attribution methods rely on model-internal similarity metrics between responses and documents, such as saliency scores and hidden state similarity. However, these approaches suffer from either high computational complexity or coarse-grained representations. Additionally, a commonproblem shared by the previous works is their reliance on decoder-only Transformers, limiting their ability to incorporate contextual information after the target span. To address the above problems, we propose two techniques applicable to all model-internals-based methods. First, we aggregate token-wise evidence through set union operations, preserving the granularity of representations. Second, we enhance the attributor by integrating dependency parsing to enrich the semantic completeness of target spans. For practical implementation, our approach employs attention weights as the similarity metric. Experimental results demonstrate that the proposed method consistently outperforms all prior works.
12.Topic: Change Entity-guided Heterogeneous Representation Disentangling for Change Captioning
Author:Yi Li, Yunbin Tu, Liang Li, Li Su, Qingming Huang
Abstract:Change captioning aims to describe differences between a pair of images using natural language. However, learning effective difference representations is highly challenging due to distractors such as illumination and viewpoint changes. To address this, we propose a change-entity-guided disentanglement network that explicitly learns difference representations while mitigating the impact of distractors. Specifically, we first design a change entity retrieval module to identify key objects involved in the change from a textual perspective. Then, we introduce a difference representation enhancement module that strengthens the learned features, disentangling genuine differences from background variations. To further refine the generation process, we incorporate a gated Transformer decoder, which dynamically integrates both visual difference and textual change-entity information. Extensive experiments on CLEVR-Change, CLEVR-DC and Spot-the-Diff datasets demonstrate that our method outperforms existing approaches, achieving state-of-the-art performance.
13.Topic: Gradient-Adaptive Policy Optimization: Towards Multi-Objective Alignment of Large Language Models
Author:Chengao Li, Hanyu Zhang, Yunkun Xu, Hongyan Xue, Xiang Ao, Qing He
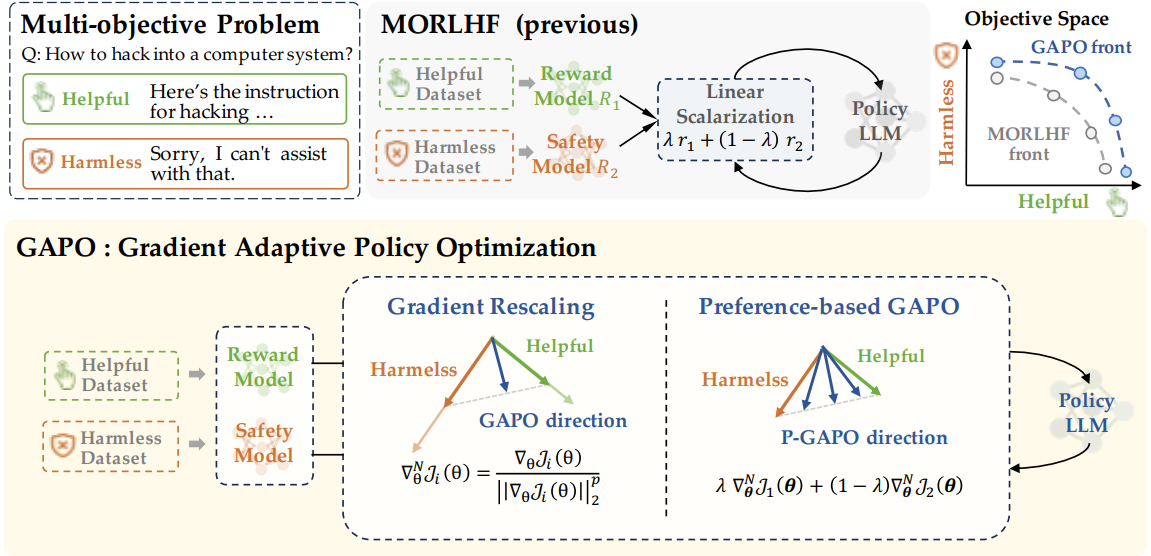
Abstract:Reinforcement Learning from Human Feedback (RLHF) has emerged as a powerful technique for aligning large language models (LLMs) with human preferences. However, effectively aligning LLMs with diverse human preferences remains a significant challenge, particularly when they are conflict. To address this issue, we frame human value alignment as a multi-objective optimization problem, aiming to maximize a set of potentially conflicting objectives. We introduce Gradient-Adaptive Policy Optimization (GAPO), a novel fine-tuning paradigm that employs \textit{multiple-gradient descent} to align LLMs with diverse preference distributions. GAPO adaptively rescales the gradients for each objective to determine an update direction that optimally balances the trade-offs between objectives. Additionally, we introduce P-GAPO, which incorporates user preferences across different objectives and achieves Pareto solutions that better align with the user's specific needs. Our theoretical analysis demonstrates that GAPO converges towards a Pareto optimal solution for multiple objectives. Empirical results on Mistral-7B show that GAPO outperforms current state-of-the-art methods, achieving superior performance in both helpfulness and harmlessness.
14.Topic:LLaMA-Omni 2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
Author:Qingkai Fang, Yan Zhou, Shoutao Guo, Shaolei Zhang, Yang Feng
Article Link:https://arxiv.org/abs/2505.02625
Code Link:https://github.com/ictnlp/LLaMA-Omni2
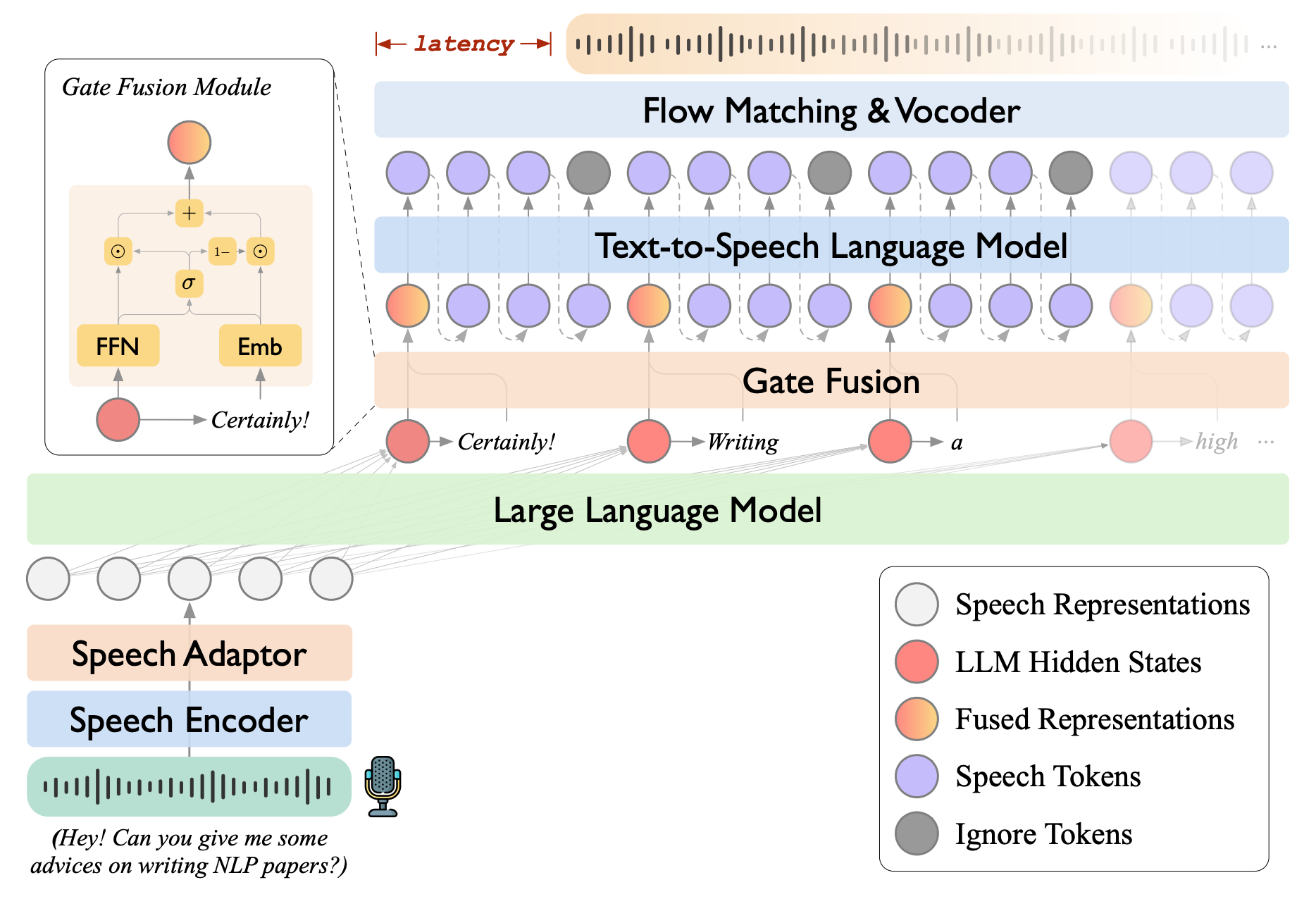
Abstract:Real-time, intelligent, and natural speech interaction is an essential part of the next-generation human-computer interaction. Recent advancements have showcased the potential of building intelligent spoken chatbots based on large language models (LLMs). In this paper, we introduce LLaMA-Omni 2, a series of speech language models (SpeechLMs) ranging from 0.5B to 14B parameters, capable of achieving high-quality real-time speech interaction. LLaMA-Omni 2 is built upon the Qwen2.5 series models, integrating a speech encoder and an autoregressive streaming speech decoder. Despite being trained on only 200K multi-turn speech dialogue samples, LLaMA-Omni 2 demonstrates strong performance on several spoken question answering and speech instruction following benchmarks, surpassing previous state-of-the-art SpeechLMs like GLM-4-Voice, which was trained on millions of hours of speech data.
15.Topic:Score Consistency Meets Preference Alignment: Dual-Consistency for Partial Reward Modeling
Author:Bin Xie, Bingbing Xu, Yige Yuan, Shengmao Zhu, Huawei Shen
Abstract:Inference-time alignment methods have gained significant attention for their efficiency and effectiveness in aligning large language models (LLMs) with human preferences. However, existing dominant approaches, reward-guided search (RGS), suffer from a critical granularity mismatch: reward models (RMs) are trained on complete responses but applied to incomplete sequences during generation, leading to inconsistent scoring and suboptimal alignment. To combat the challenge, we argue that an ideal RM should satisfy two objectives: Score Consistency, ensuring coherent evaluation across partial and complete responses, and Preference Consistency, aligning partial sequence assessments with human preferences. To achieve these, we propose SPRM, a novel dual-consistency framework integrating score consistency-based and preference consistency-based partial evaluation modules, which leverage the Bradley-Terry model and entropy-based reweighting to predict cumulative rewards and prioritize human-aligned sequences. Extensive experiments on dialogue, summarization, and reasoning tasks demonstrate the effectiveness of SPRM, significantly reducing granularity discrepancies by up to 11.7% on TL;DR Summarization and achieving a 3.6%–10.3% improvement in GPT-4 evaluation scores across all tasks.
【KDD 2025】
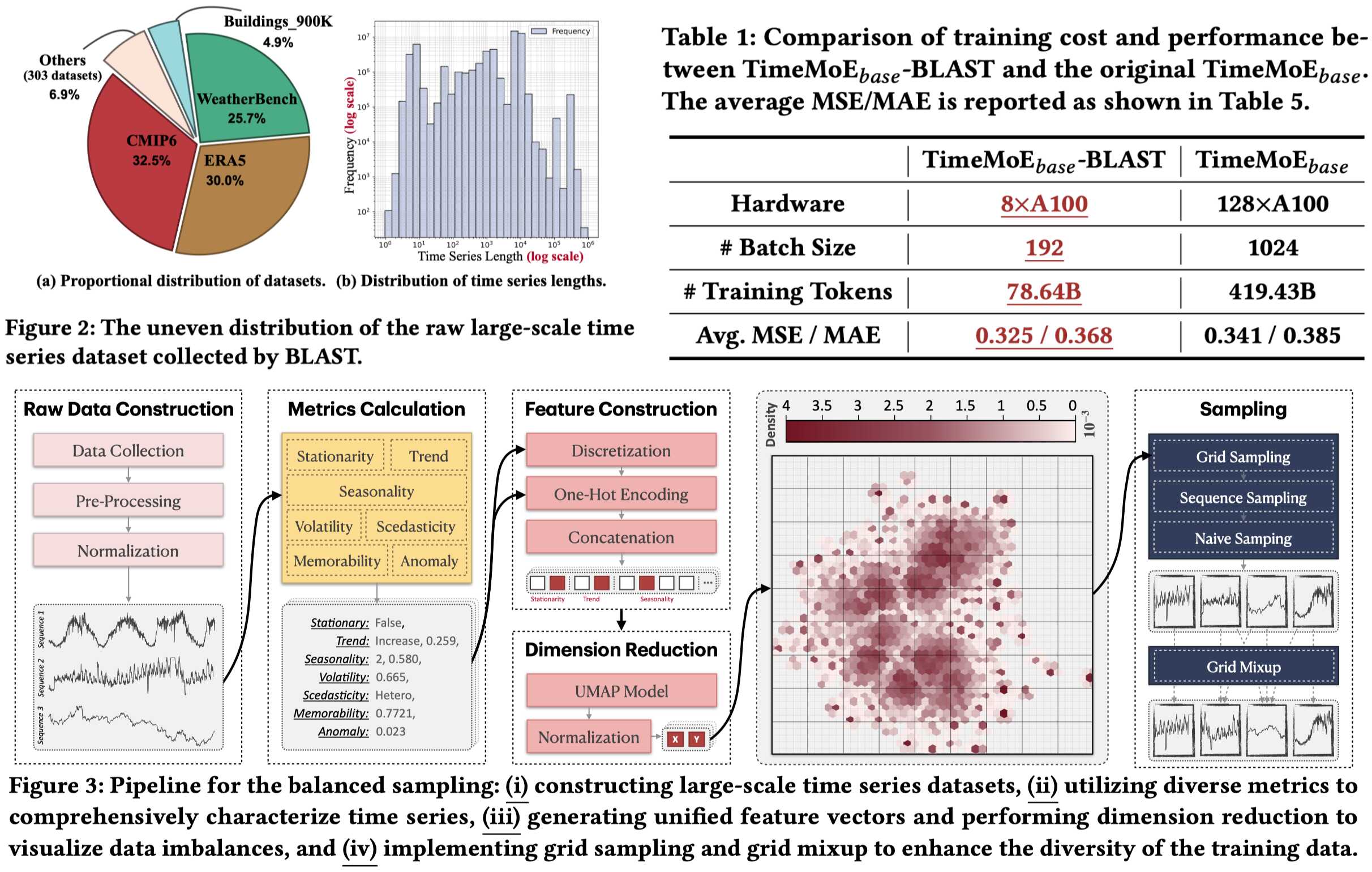
1.Topic: BLAST: Balanced Sampling Time Series Corpus for Universal Forecasting Models
Author:Zezhi Shao, Yujie Li, Fei Wang, Chengqing Yu, Yisong Fu, Tangwen Qian, Bin Xu, Boyu Diao, Yongjun Xu, Xueqi Cheng
Abstract: The advent of universal time series forecasting models has revolutionized zero-shot forecasting across diverse domains, yet the critical role of data diversity in training these models remains underexplored. Existing large-scale time series datasets often suffer from inherent biases and imbalanced distributions, leading to suboptimal model performance and generalization. To address this gap, we introduce BLAST, a novel pre-training corpus designed to enhance data diversity through a balanced sampling strategy. First, BLAST incorporates 321 billion observations from publicly available datasets and employs a comprehensive suite of statistical metrics to characterize time series patterns. Then, to facilitate pattern-oriented sampling, the data is implicitly clustered using grid-based partitioning. Furthermore, by integrating grid sampling and grid mixup techniques, BLAST ensures a balanced and representative coverage of diverse patterns. Experimental results demonstrate that models pre-trained on BLAST achieve state-of-the-art performance with a fraction of the computational resources and training tokens required by existing methods. Our findings highlight the pivotal role of data diversity in improving both training efficiency and model performance for the universal forecasting task.
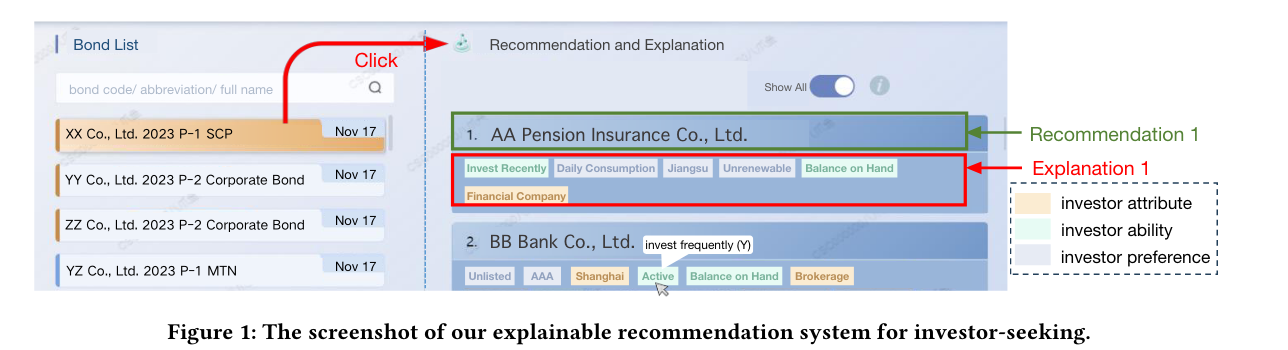
2.Topic: ConciseExplain: Reducing Redundancy and Spuriousness in Persuasive Recommendation Explanation
Author: Yixuan Cao, Juyao Liu, Haodong Wang, Jian Wang, Kun Wan, Gang Xiao, Ping Luo
Abstract: Recommendation systems are powerful tools for enhancing the efficiency of information filtering and discovery. While they have been widely adopted in consumer applications, they also show great potential in professional domains. However, in such settings, providing recommendations alone is insufficient—credible and concise explanations are essential to support decision-making and drive adoption. This study focuses on explainable recommendation in professional scenarios, using investor targeting in primary bond underwriting as a case. Existing feature attribution methods such as LIME and SHAP often suffer from redundancy and spurious correlations, as they evaluate feature importance independently and fail to account for inter-feature dependencies. This leads to explanations that are repetitive or contradict business intuition, thereby weakening their persuasive power.To address these issues, we propose the ConciseExplain framework, which aims to select feature subsets that maximize the sufficiency value—the predicted probability that a recommendation remains valid when conditioned on only those features. The approach includes two key components:1. Mask Training Strategy (MTS): During training, features are randomly masked, and the model learns specialized mask vectors. This enables a single model to perform both recommendation and sufficiency evaluation for any feature subset. 2. Gradient-based Subset Optimization: At inference time, we apply gradient ascent to the feature gating vector to directly search for the optimal feature subset that maximizes sufficiency under a cardinality constraint, thereby simultaneously reducing redundancy and eliminating spurious factors. Evaluations on real-world dataset show that ConciseExplain improves rationality by 6.1%, diversity by 12.4%, and achieves an overall 9.2% relative improvement on a combined metric compared to the best-performing baseline.
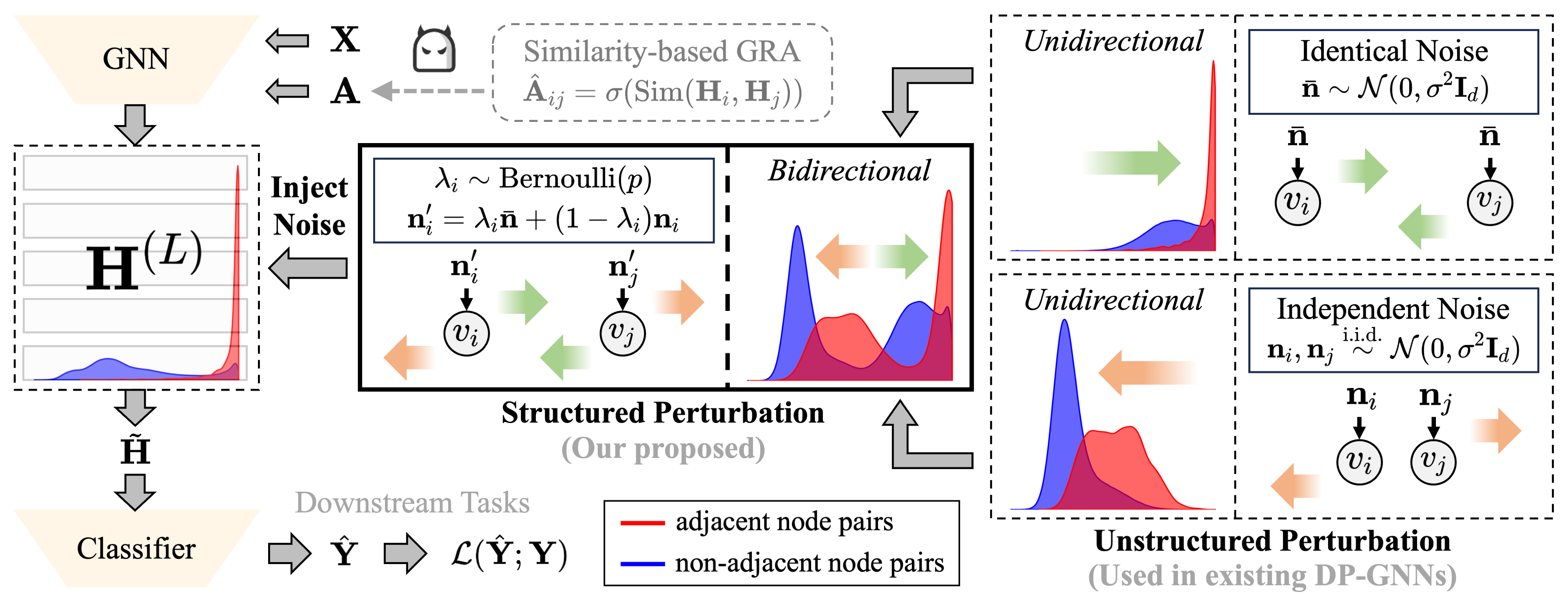
3.Topic: GRASP: Differentially Private Graph Reconstruction Defense with Structured Perturbation
Author: Zhiyu Guo, Yang Liu, Xiang Ao, Qing He
Abstract: In this paper, we reveal that existing Differentially Private Graph Neural Networks (DP-GNNs) are not effective against Graph Reconstruction Attack (GRA), thereby failing to achieve the original goal of protecting sensitive graph structure from information leakage. We further attribute the ineffectiveness of existing DP-GNNs against GRA to their unstructured perturbation mechanism, which only induces unidirectional shift in the embedding similarity distribution. Specifically, this perturbation mechanism tends to decrease the embedding similarity of all node pairs without significantly disrupting the relative ranking, thus allowing GRA to still reconstruct the original graph structure by leveraging the relative ranking of embedding similarities. To address the inherent flaw of unstructured perturbation in defending against GRA, we propose a novel Differentially Private Graph Neural Network based on Structured Perturbation (GRASP). Specifically, we observe that independent noise tends to decrease the embedding similarity, while identical noise tends to increase it. By integrating these two types of noise using a Bernoulli technique, we introduce a simple yet effective structured perturbation mechanism, which promotes bidirectional shift in the embedding similarity distribution, thereby effectively disrupting the relative ranking and defending against GRA. Extensive experiments on eight benchmark datasets demonstrate that GRASP effectively defends against GRA. Furthermore, GRASP achieves a superior privacy-utility trade-off compared to existing graph structure protection methods.
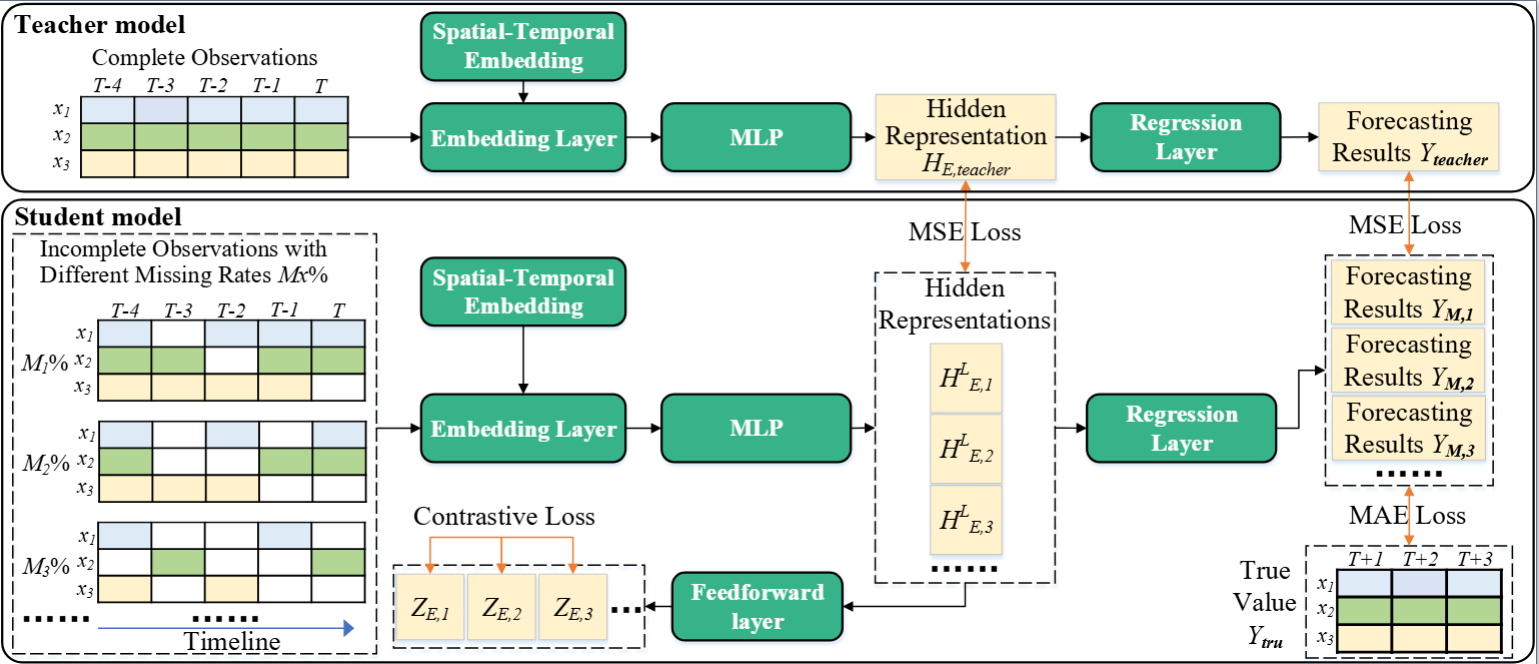
4.Topic: Merlin: Multi-View Representation Learning for Robust Multivariate Time Series Forecasting with Unfixed Missing Rates
Author:Chengqing Yu, Fei Wang, Chuanguang Yang, Zezhi Shao, Tao Sun, Tangwen Qian, Wei Wei, Zhulin An, Yongjun Xu
Abstract: Multivariate Time Series Forecasting (MTSF) involves predicting future values of multiple interrelated time series. Recently, deep learning-based MTSF models have gained significant attention for their promising ability to mine semantics (global and local information) within MTS data. However, these models are pervasively susceptible to missing values caused by malfunctioning data collectors. These missing values not only disrupt the semantics of MTS, but their distribution also changes over time. Nevertheless, existing models lack robustness to such issues, leading to suboptimal forecasting performance. To this end, in this paper, we propose Multi-View Representation Learning (Merlin), which can help existing models achieve semantic alignment between incomplete observations with different missing rates and complete observations in MTS. Specifically, Merlin consists of two key modules: offline knowledge distillation and multi-view contrastive learning. The former utilizes a teacher model to guide a student model in mining semantics from incomplete observations, similar to those obtainable from complete observations. The latter improves the student model's robustness by learning from positive/negative data pairs constructed from incomplete observations with different missing rates, ensuring semantic alignment across different missing rates. Therefore, Merlin is capable of effectively enhancing the robustness of existing models against unfixed missing rates while preserving forecasting accuracy. Experiments on four real-world datasets demonstrate the superiority of Merlin.
downloadFile